





![]()
CONFETTI is a multi-objective method for generating counterfactual explanations for multivariate time series. It identifies the most influential subsequences, constructs a minimal perturbation, and optimizes it under multiple objectives to produce sparse, realistic, and confidence-increasing counterfactuals
CONFETTI is model-agnostic and works with any deep learning classifier, differentiable or not.
- Multi-objective optimization using NSGA-III
- Works for any Keras/Scikit-learn multivariate time series classifier
- Optional use of class activation maps for feature-weighted perturbations
- Generates multiple diverse counterfactuals per instance
- Parallelized counterfactual generation
- Built-in utilities for:
- loading datasets
- computing CAM weights
- visualizing counterfactual explanations
pip install confetti-tsgit clone https://github.com/serval-uni-lu/confetti.git
cd confetti
uv venv
source .venv/bin/activate
uv pip install -e .Requirements:
- Python 3.12+
- NumPy, pandas
- Keras 3.x
- TensorFlow
- Pymoo
- tslearn
All dependencies are handled automatically via pyproject.toml.
Below is a minimal end-to-end example based on the demo_confetti.ipynb notebook.
It loads a trained model, prepares a dataset, and generates counterfactuals for a single instance.
from confetti import CONFETTI
from confetti.attribution import cam
from confetti.utils import load_multivariate_ts_from_csv
from confetti.visualizations import plot_counterfactual
import keras
# Load model
model_path = "examples/models/toy_fcn.keras"
model = keras.models.load_model(model_path)
# Load dataset in (n_samples, time_steps, n_features) format
X_train, y_train = load_multivariate_ts_from_csv("examples/data/toy_train.csv")
X_test, y_test = load_multivariate_ts_from_csv("examples/data/toy_test.csv")
# Select instance to explain
instance = X_test[0:1]
# Generate CAM weights for training data (optional)
training_weights = cam(model, X_train)
# Initialize explainer
explainer = CONFETTI(model_path=model_path)
# Generate counterfactuals
results = explainer.generate_counterfactuals(
instances_to_explain=instance,
reference_data=X_train,
reference_weights=training_weights, # or None if not available
)
# Visualize the best counterfactual
plot_counterfactual(
original=results[0].original_instance,
counterfactual=results[0].best,
cam_weights=results[0].feature_importance,
cam_mode="heatmap",
title="Counterfactual Explanation"
)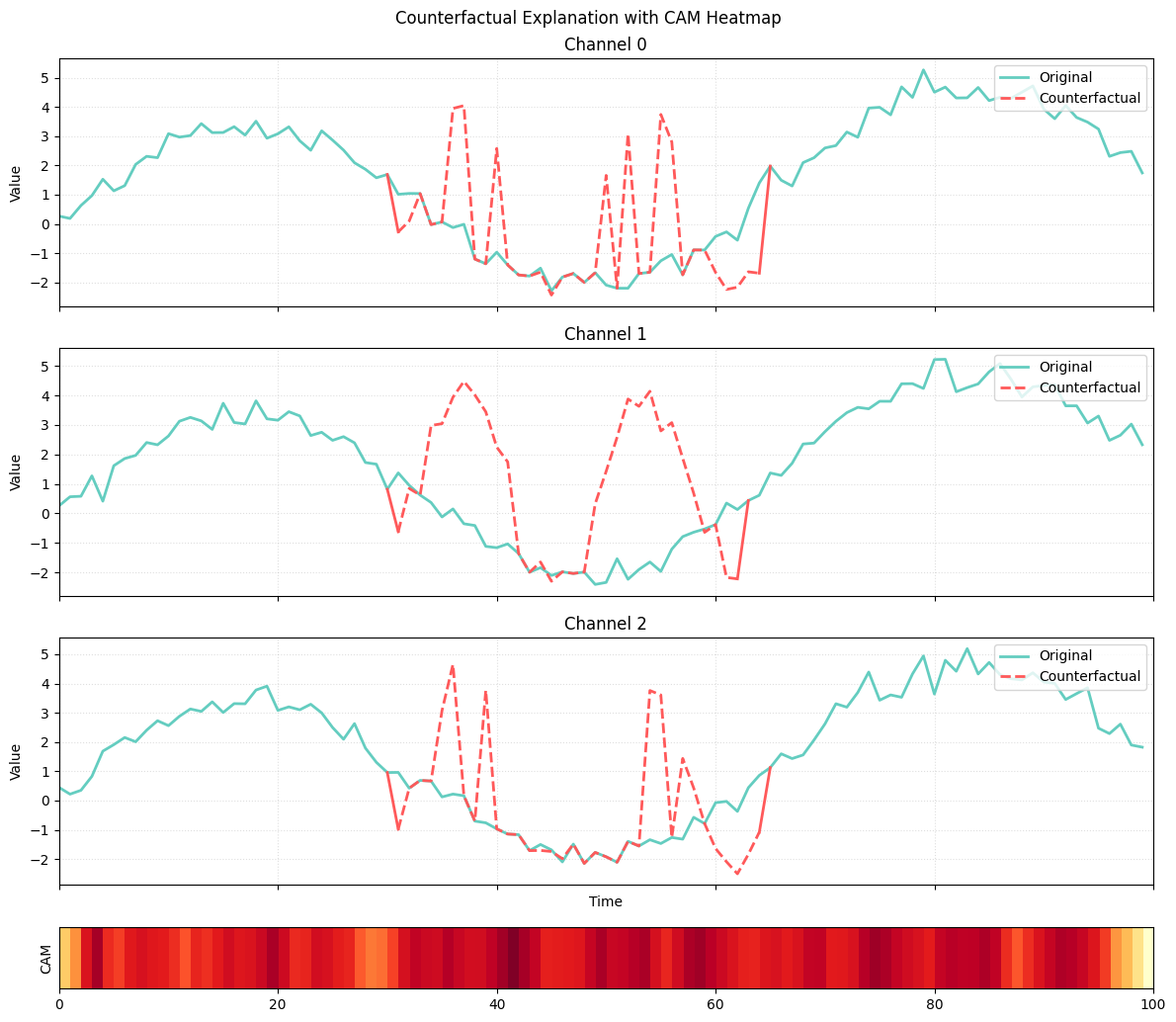
In the visualization:
- green curves represent the original instance
- red curves represent the counterfactual subsequence
- the heatmap corresponds to CAM scores of the nearest unlike neighbor
The alignment between CAM activation and the altered subsequence shows how CONFETTI uses attribution to target meaningful areas of the time series.
The full documentation, including usage guides, API reference, and examples, is available at:
👉 https://confetti-ts.readthedocs.io/en/latest/
CONFETTI is released under the MIT License.
If you use CONFETTI in your research, please consider citing the following paper:
@inproceedings{cetina2026counterfactual,
title={Counterfactual Explainable AI (XAI) Method for Deep Learning-Based Multivariate Time Series Classification},
author={Cetina, Alan Gabriel Paredes and Benguessoum, Kaouther and Lourenco, Raoni and Kubler, Sylvain},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={40},
number={21},
pages={17393--17400},
year={2026}
}
To replicate the experiments described in the paper, use the paper branch of this
repository. It contains the experiment scripts, model configurations, and dataset handling
used in the publication.