Udacity Artificial Intelligence ND is an advanced course. We built projects for broad field of artificial intelligence.
- Use HMM to Recognize American Sign Language,
- Domain-Independent Planner,
- Adversarial Search Agent,
- Solving Sudoku with AI
Udacity Deep Learning is an ongoing course. For academic integrity, the source code of my implementation are private. If you like to view the code, please let me know.
The overall goal of this project is to build a word recognizer for American Sign Language video sequences, demonstrating the power of probabalistic models. In particular, this project employs hidden Markov models (HMM's) to analyze a series of measurements taken from videos of American Sign Language (ASL) collected for research (see the RWTH-BOSTON-104 Database). In this video, the right-hand x and y locations are plotted as the speaker signs the sentence.
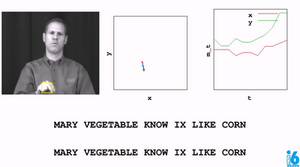
I implemented a half of dozen features. Below is an example of feature selections:

The Model Selectors:
- Cross Validation fold, use sklearn KFold
- Bayesian information Criterion, use hmmlearn GaussianHMM
- Discriminative Information Criterion, use hmmlearn GaussianHMM
The Recognizer trains the models for each word and test the models with sentences for each combination of features and selectors. The best result I have achieved is 60% accuracy or 40% error rate (WER), see below. Under 60% WER is considerated as a reasonable model.
**** WER = 0.4044943820224719
Total correct: 106 out of 178
Video Recognized Correct
=====================================================================================================
100: POSS NEW CAR BREAK-DOWN POSS NEW CAR BREAK-DOWN
2: JOHN WRITE HOMEWORK JOHN WRITE HOMEWORK
.......
 |
This project is to solve deterministic logistics planning problems for an Air Cargo transport system using a planning search agent. With progression search algorithms, optimal plans for each problem will be computed. implement domain-independent heuristics to aid the agent search. |
The code needed be modified were my_air_cargo_problems.py and my_planning_graph.py. The test code, test result and heuristic analysis are shown in paper Heuristic Analysis for the Planning Search Agent
code example
def get_actions(self):
"""
This method creates concrete actions (no variables) for all actions in the problem
domain action schema and turns them into complete Action objects as defined in the
aimacode.planning module. It is computationally expensive to call this method directly;
however, it is called in the constructor and the results cached in the `actions_list` property.
Returns:
----------
list<Action>: list of Action objects
"""
# concrete actions definition: specific literal action that does not include variables as with the schema
# for example, the action schema 'Load(c, p, a)' can represent the concrete actions 'Load(C1, P1, SFO)'
# or 'Load(C2, P2, JFK)'. The
def load_actions():
"""Create all concrete Load actions and return a list
:return: list of Action objects
"""
loads = []
for cargo in self.cargos:
for plane in self.planes:
for ap in self.airports:
precond_pos = [expr("At({}, {})".format(cargo, ap)), expr("At({}, {})".format(plane, ap))]
precond_neg = []
effect_add = [expr("In({}, {})".format(cargo, plane))]
effect_rem = [expr("At({}, {})".format(cargo, ap))]
load = Action(expr("Load({}, {}, {})".format(cargo, plane, ap)),
[precond_pos, precond_neg],
[effect_add, effect_rem])
loads.append(load)
return loads
wrote research paper "The History of AI Planning"
 |
The task is to develop an adversarial search agent to play a chess-like game "Isolation". Isolation is a deterministic, two-player game of perfect information in which the players alternate turns moving a single piece from one cell to another with only L-shaped movements (like a knight in chess) on a board. Whenever either player occupies a cell, that cell becomesblocked for the remainder of the game. The first player with no remaining legal moves loses, and the opponent is declared the winner. |
The code needed be modified was game_agent.py. The test code, test result and heuristic analysis are shown in paper Heuristic Analysis for Game-Playing Agent
Code example ofpositive evaluation
def custom_score(game, player):
"""Calculate the heuristic value of a game state from the point of view of the given player.
This should be the best heuristic function for your project submission. Note: this function
should be called from within a Player instance as `self.score()`.
Parameters
----------
game : `isolation.Board`
An instance of `isolation.Board` encoding the current state of the
game (e.g., player locations and blocked cells).
player : object
A player instance in the current game (i.e., an object corresponding to
one of the player objects `game.__player_1__` or `game.__player_2__`.)
Returns
-------
float
The heuristic value of the current game state to the specified player.
<=> based on improved_score. randonly reduce score a bit if the location is close to edge,
"""
if game.is_loser(player):
return float("-inf")
if game.is_winner(player):
return float("inf")
own_moves = len(game.get_legal_moves(player))
opp_moves = len(game.get_legal_moves(game.get_opponent(player)))
score = own_moves - opp_moves
w, h = game.width / 2., game.height / 2.
y, x = game.get_player_location(player)
ratio = (abs(h - y) + abs(w - x))/(w+h) # how close to center
return score * (2 + ratio) # weight score more than the closeness
Wrote a review on IBM DeepBlue and Google AlphaGO "From Rain Man to Thinking Man, A Huge Leap in AI Made by AlphaGo"
code example of search
def search(values):
values = reduce_puzzle(values)
if not values:
return False # end, out
if all(len(v) == 1 for v in values.values()):
return values # got values, out
unsolved = {k: v for k, v in values.items() if len(v) > 1}
if unsolved:
sorted_unsolved = sorted(unsolved.items(), key=lambda x: len(x[1]))
for s, v in sorted_unsolved:
for d in v:
copy_of_values = values.copy()
copy_of_values[s] = d
attempt = search(copy_of_values) # recurse
if attempt:
return attempt
print("unsolved=", unsolved)
Screenshot of run result
