Releases: lossless-group/perplexed-plugin
0.3.0
0.3.0 turns Perplexed into a serious analyst tooling layer for Venture Capital, Private Equity, and equities-trading workflows. Three new directory templates produce 6-9K-word cited analyst drafts in a single Perplexity Deep Research run. Underneath them, four infrastructure fixes turn deep-research from a brittle "might work" workflow into something you can put real analyst time behind.
Why care?
If your work involves naming the actual companies in a market category, mapping who's playing where in an emerging market, or profiling the open specs an investment thesis depends on — 0.3.0 is the release where Perplexed becomes a serious analyst tooling layer, not just a notes-with-citations plugin.
Three new directory templates. Each produces a 6-9K-word cited analyst draft in a single Perplexity Deep Research run. Each was designed for the kind of document a VC analyst, PE associate, or equities-trading desk strategist hands to a partner or IC:
- Market-category profiles (
concepts/Market-Categories/) name the companies in a category, sorted into three explicit financial-stage tiers — Incumbents (public / late-stage private / PE-owned), Challengers (Series C+ scale-ups), Innovators (Pre-Seed through Series B) — with separate Why Now / What's Happening sections covering CAGR and category-creation momentum, and a fully-sourced Industry Coverage section sub-grouped into Market Reports (Gartner, IDC, Forrester, ABI) / Industry Articles / Financial News (Bloomberg, FT, Pitchbook). - Market-map drafts (
lost-in-public/market-maps/) produce the analyst memo itself — 4-8 sub-segments, 20-40 named innovator cards with funding stage and lead investor, Market Dynamics with cited sizing data and capital concentration, and a Frontier section with open questions framed as questions. - Standards-and-specs profiles (
Sources/Standards-and-Specs/) turn an open protocol or convention into a strategic-context document — five-way authority typing (de-jure / consortium / vendor-led-open / community / de-facto), three-tier structural adoption framing plus notable holdouts, named editors, stewardship-transition stories, named public critics with their arguments. Surfaces what an analyst needs to know about a spec: is it surviving its originating vendor, who has it captured, who's working to break the capture.
Four infrastructure fixes — each one solving a class of "deep-research silently produces broken output" failure mode that would otherwise have kept the analyst-grade workflow brittle:
- Per-chunk idle-timeout discipline. The timer that decides "is this stream still alive?" is now armed per-chunk, not once per request. A healthy slow stream completes naturally regardless of total duration; a silently-stalled one fails in seconds, not at the wall-clock ceiling. Ported from the legacy
PerplexityModalflow into the directory-template runtime. - Per-template
request-timeout-ms:cft override. Becomes the optional absolute wall-clock ceiling (belt-and-suspenders backstop on top of the idle timer). Set to0to disable entirely and rely on idle-only safety — the recommended setting for the two new analyst-grade templates. - Per-template
max-tokens:cft override. Fixes the silent-truncation pathology where Perplexity's default output cap (~8,192 tokens, ~6K words forsonar-deep-research) was ending the stream cleanly mid-template — full sources footer, no Notice, no truncation flag, looking like a healthy completion that just happened to be missing the back half. The three deep-research templates ship withmax-tokens: 24000(~18K-word budget). - Strengthened rendering-discipline partials.
mermaid-discipline.mdrewritten with paired BAD/GOOD examples throughout, the&escape rule, an explicit\nvs<br/>ban, a six-item self-check before emit, and a simplify-rather-than-break ethos. Newlatex-discipline.mdpartial covers Obsidian MathJax delimiters and$escaping. Both wired intoconcept-profile.md.
Diagnostic vocabulary for streaming failures
| Symptom | Cause |
|---|---|
| Mid-sentence cutoff (ends with a partial word); no sources footer; "stream went idle" Notice or no Notice at all | Wall-clock timer (request-timeout-ms:) or idle timer (stream-idle-timeout-ms:) fired during streaming |
| Clean section-end cutoff; sources footer renders correctly with all citations; no Notice | Perplexity max_tokens cap; stream completed via finish_reason: "length" |
The three streaming knobs (request-timeout-ms, stream-idle-timeout-ms, max-tokens) are independent — a template can hit any of them, all of them, or none. The three new deep-research templates set all three generously so analyst-grade runs land reliably.
Editorial discipline diverges by template
The three new deep-research templates share a common technical substrate but apply different editorial stances on big tech:
- Market-map caps big tech at 1-of-5-10 in any sub-bucket to counteract training-data bias — the analyst's job is to name the named operators driving the curve.
- Standards-and-specs names big tech freely in the Incumbents tier (large dominant implementations) and aggressively in the Innovators tier (where the next extensions come from). Suppression would distort the implementation landscape.
- Market-category names big tech as the FIRST move in Incumbents because for a category profile, knowing the incumbents IS the work product.
Each template's system prompt states its editorial stance explicitly so a future template-modifier doesn't accidentally cross-pollinate the wrong stance across templates.
Upgrade notes
Vault template drift — the gotcha worth five seconds of attention. If your Content-Dev/Templates/concept-profile.md was seeded before today, it may be missing the {{include: mermaid-discipline}} and {{include: latex-discipline}} directives. Without them, every concept-profile run generates Mermaid with no rendering rules in scope at all, producing broken diagrams 4-of-5 times. Open the file, find the Defining and Describing section, and insert both directives immediately after the "render a mermaid codefence here" instruction. The re-seed button won't add them — it only writes missing files.
Re-seed pulls in the new templates and the new partial. The seven shipped templates plus the two partials are bundled into main.js. After upgrading, click Settings → Directory templates → Re-seed templates to write the new files into your vault. The button only adds files whose filenames don't already exist; nothing existing gets overwritten. You'll see market-map-profile.md, standards-and-specs-profile.md, market-category-profile.md appear in templates and latex-discipline.md appear in partials.
Backward compatibility. All cft-block additions are opt-in. Templates that don't declare the new knobs inherit sensible defaults. The four pre-0.3.0 templates (concept, vocabulary, source, toolkit) run unchanged.
Plugin-level default request timeout bumped 10 min → 30 min. Visible in Settings → Directory templates → Request timeout (ms). If you had previously set a custom value, it's preserved.
Deferred to 0.4.x
Three follow-ups that surfaced during the 0.3.0 work cycle:
- A
cf_finish_reasonfrontmatter stamp on every run — would have made the max-tokens diagnostic instant instead of an investigation. - A "Continue directory template on current file" command — for runs cut off by max-tokens, would re-prompt with only the missing sections plus URL-keyed citation merge.
- A "diff and patch user files" mode for re-seed — the vault-drift bug we caught is structural: re-seed only writes missing files, so partial/template improvements never reach users who've already seeded.
Compatibility
minAppVersion: 1.8.10 — unchanged from 0.2.1. Desktop-only — unchanged. No new external dependencies; the three new templates and two partials are bundled into main.js at build time. The cleanup pipeline behavior (think-block wrap, image-marker swap, sources footer) is unchanged.
0.2.1
Directory-template runs with sonar-deep-research were quietly discarding ~99% of every response — the streaming reader was taking the wrong field. 0.2.1 fixes that, keeps citations even when a long research stream drops mid-flight, adds a per-run model picker to the run dialog, and rebuilds the toolkit-profile template so the model searches the product's real name and triages SEO slop instead of citing it.
Why care?
If you generate research notes with Perplexed's directory templates — the "Apply directory template to current file" workflow — 0.2.1 is the release where the deep-research path actually works.
sonar-deep-research runs now keep their output. Perplexity's deep-research model does all its work server-side, then delivers the entire finished document — often 10,000+ characters — in the first event of its streaming response, in a field the plugin wasn't reading. The reader took delta.content (correct for the lighter sonar models, which stream token-by-token); on a deep-research response that field holds only a ~75-character tail fragment of a 10,000-character report. The other 99% arrived on the wire and was thrown away. toolkit-profile shipped with sonar-deep-research as its default model — so it was the default that was broken. Fixed.
Citations survive a dropped connection. Deep research holds a stream open for minutes; a WiFi roam or idle socket mid-stream used to discard everything, including the citations deep research delivers up front. A cut-off run now keeps whatever content and sources arrived, writes the citations footer anyway, and tells you it was truncated.
You pick the model when you run. "Apply directory template" now opens a run dialog with a model dropdown — and the loading toast finally names the model actually running, instead of a hardcoded "deep research" string.
What's new
Deep-research streaming — read the snapshot, not the fragment
Both streaming paths now treat Perplexity's cumulative message.content snapshot as the source of truth and append only the new tail.
| Model | How it streams | Old reader | 0.2.1 reader |
|---|---|---|---|
sonar, sonar-pro |
Token-by-token deltas | Worked | Works |
sonar-deep-research |
Whole document in event 1, then tiny deltas | ~75 of ~10,234 chars | Full document |
Citations that survive a timeout
A dropped or timed-out stream no longer discards the run. The runner returns its partial content and the sources it already received, writes the citations footer, and shows a "stream cut off — saved partial content with N sources, re-run to complete" notice. The deep-research idle timeout was lengthened (90s → 270s) since deep research legitimately holds the socket silent while it researches.
A model picker in the run dialog
"Apply directory template to current file" opens a dialog with a template dropdown and a model dropdown — sonar-pro, sonar-reasoning-pro, sonar, sonar-reasoning, sonar-deep-research. The model defaults to the template's cft model: and overrides it for that run only. The cf_last_run_model frontmatter stamp records the model that actually ran.
Domain scoping — cf_search_domains
New search_domain_filter support: a cf_search_domains: list in a target file's frontmatter (entity-specific) or a search-domains: key in a template's cft block (generic). Plain entries allowlist, a leading - denylists, capped at 10. Job boards (Indeed, Glassdoor, ZipRecruiter, USAJobs) are denied automatically — a job listing is never a product source. Allowlisting is a last resort for collision-heavy names, not the everyday workflow.
The toolkit-profile template, rebuilt
The shipped toolkit-profile template's system prompt was overhauled: it anchors the entity on its real name ({{basename}}) instead of the scraped marketing tagline; it tells the model to triage source quality — editorial authority over SEO ranking, judge each page on its merits — rather than trusting or hard-banning by domain; it adds a hard "search, don't recall" instruction and per-section length ceilings. Default model is now sonar-pro, with sonar-deep-research one dialog click away.
Longer request timeout
The directory-template request timeout default moved 5 minutes → 10, so a sonar-deep-research run has room to finish.
Verify the release assets
Every release asset is signed via GitHub's artifact attestation system. Before manual install, verify provenance:
gh attestation verify main.js --repo lossless-group/perplexed-plugin
gh attestation verify manifest.json --repo lossless-group/perplexed-plugin
gh attestation verify styles.css --repo lossless-group/perplexed-pluginExit code 0 means the file came out of a legitimate build of the source repo.
The Lossless Group plugin family
| Plugin | What it does |
|---|---|
| Cite Wide | Stable hex-identifier citations + URL-based dedupe + LLM-paste research conversion |
| Image Gin | Recraft + Ideogram image generation, Magnific stock search, ImageKit CDN, drag-gate |
| Perplexed (this release) | Source-cited research from Perplexity, Claude, Gemini, Perplexica, or LM Studio + per-directory templates |
| Metafetch | Pull OpenGraph metadata into note frontmatter via OpenGraph.io or Microlink |
If Perplexed saves you time, buy us a coffee. The plugins are free; the coffee keeps the next one coming.
Full release narrative
Marketing-grade narrative with the deeper context, the full eight-file changeset, and what's next: changelog/releases/0.2.1.md.
0.2.0
Ask Gemini joins Perplexity, Claude, Perplexica, and LM Studio as Perplexed's fourth research provider — Google Search grounded, with the per-claim citation attribution Claude's web_search round-trip silently loses.
Why care?
If you fill research notes in Obsidian — concept profiles, source dossiers, vocabulary entries, anything where the citation matters as much as the body — Perplexed 0.2.0 changes two things that show up the moment you use it.
You have a fourth research provider, and it cites better than the three before it. Ask Gemini joins the lineup with full Google Search grounding turned on by default. Where Claude's newer web_search_20260209 drops per-claim citations on the round-trip through its dynamic-filtering sandbox (sources come back, attribution doesn't — text blocks return with citations: null), Gemini's groundingSupports[] carries the segment-to-source mapping intact. So the ### Citations footer that lands in your note is actually attached to the prose above it, with the verbatim quote per source.
Your shared editorial rules stop being duplicated across templates. Four directory templates (concept, vocabulary, source, toolkit) used to repeat the same mermaid-discipline / citation-enforcement / image-placement / research-framing guidance inside each one, with some of it hardcoded in TypeScript users couldn't touch. Now those rules live in vault-visible partials/ and preambles/ folders. Fix the mermaid rules once in partials/mermaid-discipline.md and every template picks the fix up on the next generation.
The full provider lineup as of 0.2.0:
| Provider | Endpoint | Cost | Best for |
|---|---|---|---|
| Perplexity | api.perplexity.ai | Paid | Source-cited research with consistent citation formatting |
| Anthropic Claude | api.anthropic.com | Paid | Longer-form reasoning with web_search and adaptive thinking |
| Google Gemini (new) | generativelanguage.googleapis.com | Free tier (no credit card) + paid | Google Search grounding with per-segment citation attribution |
| Perplexica / Vane | localhost:3030 (self-hosted) | Free | Privacy-sensitive research; runs entirely on your machine |
| LM Studio | localhost:1234 (local) | Free | Local-only inference, no network |
Open Obsidian → Settings → Community Plugins → Browse → "Perplexed" → Install → Enable, then paste a Gemini API key from aistudio.google.com (free tier, no credit card required) into Settings → Perplexed → Gemini (Google).
Ask Gemini — what's in the box
A new Ask Gemini command opens a modal mirroring the Ask Claude shape: question textarea, model dropdown, behavior toggles, Cmd-Enter to submit. Default model is gemini-flash-latest (Google's always-current Flash alias, free-tier friendly) — gemini-pro-latest and pinned gemini-2.5-pro / gemini-2.5-flash are also selectable.
When google_search grounding is enabled (default on), the plugin streams the answer into your note and parses two layers of provenance from the response:
| Layer | Field | What it gives you |
|---|---|---|
| Page-level | groundingChunks[] |
URL + title per page Gemini consulted |
| Segment-level | groundingSupports[] |
Text span (segment.text) → indices into groundingChunks[] |
The plugin walks both layers and merges them by URL: page-level chunks become URL-and-title fallbacks; segment-level supports enrich them with the verbatim quote Gemini grounded against. Citation footer mirrors Claude's exactly ([N]: [Title](url). > cited_text) so Cite Wide's hex-substitution pass works on Gemini output too.
The two Gemini-specific quirks Perplexed handles for you
Anyone who's wired the raw Gemini API will recognize these:
-
chunk.web.uriis a short-lived Google redirect. The URL Google returns is avertexaisearch.cloud.google.com/grounding-api-redirect/AUZIY…redirect that expires roughly 30 days after the response. Naive "just write the URL we got" means every cited note rots on a clock. Perplexed resolves each redirect via Obsidian'srequestUrl(Node-side, no CORS friction) and parses the destination page's<link rel="canonical">/<meta property="og:url">for the durable source URL — and parses<meta property="og:title">/<title>for the real page title. So a citation that would naively render as[bloomberg.com](vertexaisearch.cloud.google.com/...)instead lands as[Bloomberg Beta — Bloomberg LP](https://www.bloomberg.com/company/bloomberg-beta/). -
searchEntryPoint.renderedContentis 5KB of inline-styled HTML. Google's grounding terms ask that this Search Suggestions chip be displayed when google_search is used; the chip itself is<style>-tag-prefixed HTML that Obsidian's Markdown renderer strips, leaving orphan<div>shells. Perplexed substitutes a Markdown-native### Google Searchessection: a bullet list of the queries Gemini actually issued, each linked togoogle.com/search?q=…so you can re-run the suggested search. Same end-user behavior, rendered in a form Obsidian can actually display.
Partials + preambles — shared template guidance, vault-visible
The four directory templates (concept-profile, vocabulary-profile, source-profile, toolkit-profile) historically duplicated their mermaid-discipline / citation-enforcement / image-placement / research-framing guidance inside each template, with some of it hardcoded in TypeScript constants users couldn't edit. 0.2.0 moves that guidance into two peer folders alongside templates/:
Content-Dev/
├── templates/ (the four profile templates)
├── partials/ (NEW — referenced from templates via {{include: name}})
│ └── mermaid-discipline.md
└── preambles/ (NEW — auto-attached to every Perplexity request)
├── inline-citation.md (was a hardcoded TS constant)
├── image-placement.md (was a hardcoded TS constant)
└── research-framing.md (was a TS function)
{{include: name}} resolves recursively (depth-limited, cycle-detected). Preambles auto-attach to every request with bundled defaults as fallback, and per-template overrides live in the cft fence: preambles: { system: [...], skip-user: [...], skip-all: true }.
What else this release brings
- Eight previously-hidden settings sections render again. A long-standing
addClass('perplexed-json-textarea is-tall')bug at two DOM API call sites was throwingInvalidCharacterError(the method takes a single token, not a space-separated string), abortingdisplay()mid-render and silently hiding every settings row after the Article Generator block. Same shape of fix as the May 19 batch that switched eightactiveDocument.createElcalls tocontainerEl.createEl. - System-prompt textareas widened to full-width 3-line rows. The three system-prompt settings used
Setting.addTextAreawhich crammed them into the 200px right edge of the row at 2 lines tall. Now each gets a name+description row on top and a full-width resizable textarea below. - Template seeder idempotent. Both "Folder already exists" and "File already exists" race conditions (Obsidian's in-memory file index lagging the adapter write) now get swallowed cleanly. No more red console lines on plugin load.
ERR_NETWORK_CHANGEDbecomes a useful sentence. WiFi roam, VPN reconnect, sleep/wake events mid-Perplexity-stream now write "Network changed mid-stream — re-run the query" into the note instead of a 30-line stack trace.- Ask Gemini modal with Google-flavored visual identity: gradient title text (blue → purple → red → yellow via
background-clip: text), Google four-color hairline under the header, Gemini-blue focus ring on the prompt textarea, gradient-on-hover CTA. Theme tokens everywhere structural so light, dark, and community themes all carry through.
Verify the release assets
Every release asset in 0.2.0 is signed via GitHub's artifact attestation system at build time (the workflow introduced in 0.1.2). Before manual install, verify provenance:
gh attestation verify main.js --repo lossless-group/perplexed-plugin
gh attestation verify manifest.json --repo lossless-group/perplexed-plugin
gh attestation verify styles.css --repo lossless-group/perplexed-pluginExit code 0 means the file came out of a legitimate build of the source repo.
The Lossless Group plugin family
| Plugin | What it does |
|---|---|
| Cite Wide | Stable hex-identifier citations + URL-based dedupe + LLM-paste research conversion |
| Image Gin | Recraft + Ideogram image generation, Magnific stock search, ImageKit CDN, drag-gate |
| Perplexed (this release) | Source-cited research from Perplexity, Claude, Gemini, Perplexica, or LM Studio + per-directory templates |
| Metafetch | Pull OpenGraph metadata into note frontmatter via OpenGraph.io or Microlink |
Together they form a research-to-publication pipeline: Perplexed generates source-cited prose, Cite Wide canonicalizes the citations to stable hex identifiers, Metafetch fills URL frontmatter with OG metadata, Image Gin generates matching imagery.
If Perplexed saves you time, buy us a coffee. The plugins are free; the coffee keeps the next one coming.
Under the hood — full per-day changelog index
Each substantive piece of work shipped in 0.2.0 has its own per-day changelog in the repo:
changelog/2026-05-19_01.md— partials + preambles paradigm; the one-line fix that resurrected 11 hidden settings sections- [`changelog/2026-05-19_0...
0.1.2
Perplexed turns Obsidian into a per-directory research workflow with Claude, Perplexity, Perplexica, and LM Studio — and starting with 0.1.2, every release asset is cryptographically attested back to the source code that built it.
Why care?
Knowledge vaults with thousands of stub files — concept notes, tool profiles, vocabulary entries — never get filled in one at a time. You stub them, you mean to come back, you never do. Eventually the vault has 1,600 nearly-empty profile files in Tooling/ and hundreds of concepts waiting in concepts/.
Perplexed lets you drop one template into a directory describing how its files should be filled in — what to research, what tone to take, what frontmatter to stamp, where the sources footer goes — and then runs source-cited research across every file in that directory in one pass. Pick your provider:
| Provider | Endpoint | Cost | Best for |
|---|---|---|---|
| Perplexity | api.perplexity.ai | Paid | Source-cited research with consistent citation formatting |
| Anthropic Claude | api.anthropic.com | Paid | Longer-form reasoning with web_search and adaptive thinking |
| Perplexica / Vane | localhost:3030 (self-hosted) | Free | Privacy-sensitive research; runs entirely on your machine |
| LM Studio | localhost:1234 (local) | Free | Local-only inference, no network |
The streaming response lands directly in your notes with citations intact. Then Cite-Wide picks up the numeric citations and converts them to stable hex identifiers. The two plugins compose: Perplexed generates, Cite-Wide canonicalises.
Open Obsidian → Settings → Community Plugins → Browse → "Perplexed" → Install → Enable.
What 0.1.2 brings
Cryptographic provenance on every release asset. Every main.js, manifest.json, and styles.css in this release is signed via GitHub's artifact attestation system (sigstore-backed, OIDC-verified) at build time. The bytes you install can be traced back to the exact commit and GitHub Actions workflow run that produced them.
Verify any release asset before you enable the plugin in your vault:
gh attestation verify main.js --repo lossless-group/perplexed-pluginExit code 0 means the file came out of a legitimate build of the source repo. Anything tampered with mid-flight fails the verification.
This matters more for Perplexed than most plugins: the plugin handles your API keys (Perplexity, Anthropic, etc.) and the research it generates may include sensitive prompts about your work. Verifiable provenance answers "is the plugin I installed the plugin I think I installed?" with cryptography rather than faith.
What it changes for users
Installing from inside Obsidian: nothing visible. The Community Plugins directory pulls the latest release the same way it always has.
Auditing before manual install: verify before you drop files into <vault>/.obsidian/plugins/perplexed/. Same gh attestation verify command as above.
How the build pipeline works now
A GitHub Actions workflow (.github/workflows/release.yml) fires on every 3-digit-semver tag push. In a clean Ubuntu runner it checks out the tagged commit, runs pnpm build, signs the three release assets via actions/attest-build-provenance@v1, and creates the GitHub Release with marketing-shape notes pulled from release-notes/<tag>.md in the repo.
Provenance is enforced by infrastructure, not maintainer discipline. Manual gh release create from a developer's machine is no longer the path — every release goes through the workflow.
The Lossless Group plugin family
Perplexed sits alongside three sibling plugins, all by The Lossless Group:
| Plugin | What it does |
|---|---|
| Cite Wide | Stable hex-identifier citations + URL-based dedupe + LLM-paste research conversion |
| Image Gin | Recraft + Ideogram image generation, Magnific stock search, ImageKit CDN, drag-gate |
| Perplexed (this release) | Source-cited research from Perplexity, Claude, Perplexica, or LM Studio + per-directory templates |
| Metafetch | Pull OpenGraph metadata into note frontmatter via OpenGraph.io or Microlink |
Together they form a research-to-publication pipeline: Perplexed generates the source-cited prose with numeric citations, Cite Wide rewrites them to stable hex identifiers, Metafetch fills the URL frontmatter with OG metadata, Image Gin generates the matching imagery. Each is independent; together they compound.
If Perplexed saves you time, buy us a coffee. The plugins are free; the coffee keeps the next one coming.
Under the hood — what shipped in this commit
.github/workflows/release.yml— the build-attest-release workflow described above. Identical structure to the workflows landing across cite-wide, image-gin, metafetch as a family-wide patternrelease-notes/0.1.2.md(this file) — the convention going forward: each release's marketing-shape body lives in the repo at this path before the tag is pushed- Version bumped 0.1.1 → 0.1.2 across
manifest.json,package.json,versions.json - No source-code changes — Directory Templates, the four shipped templates (concept / vocabulary / source / toolkit), the first-run seeder, the Claude provider integration, the wide modals, all behave identically to 0.1.1
0.1.1 — Template system, Directory support, Claude support, Marketplace submission release
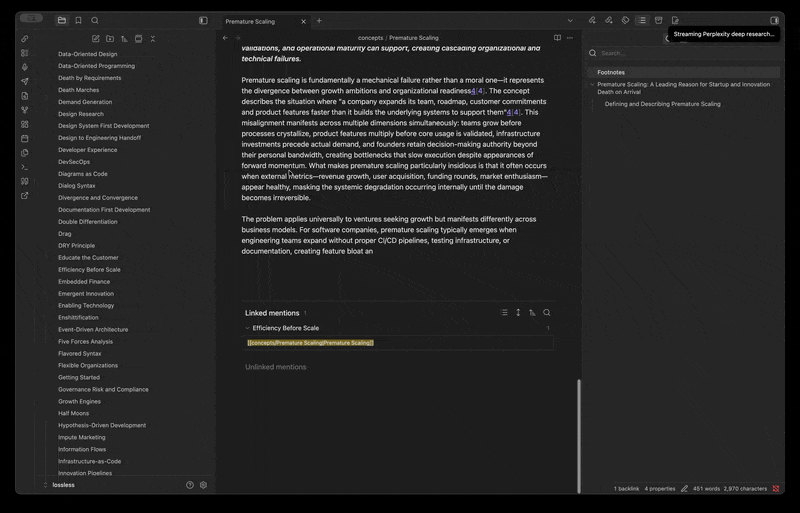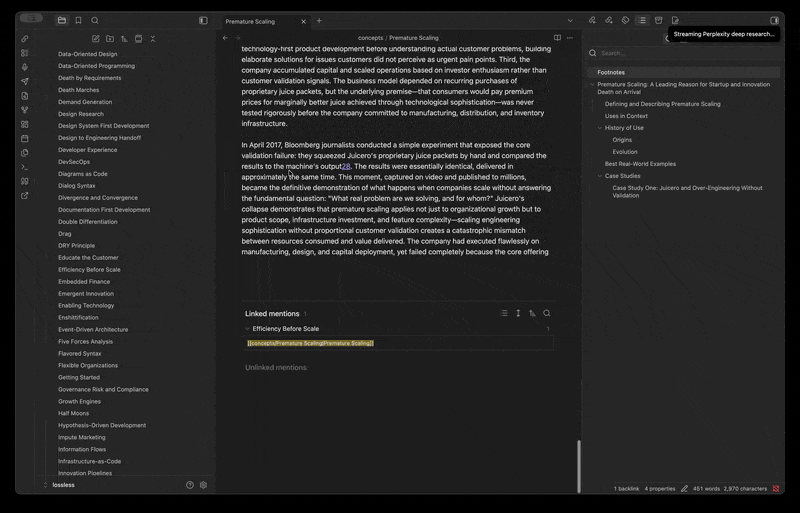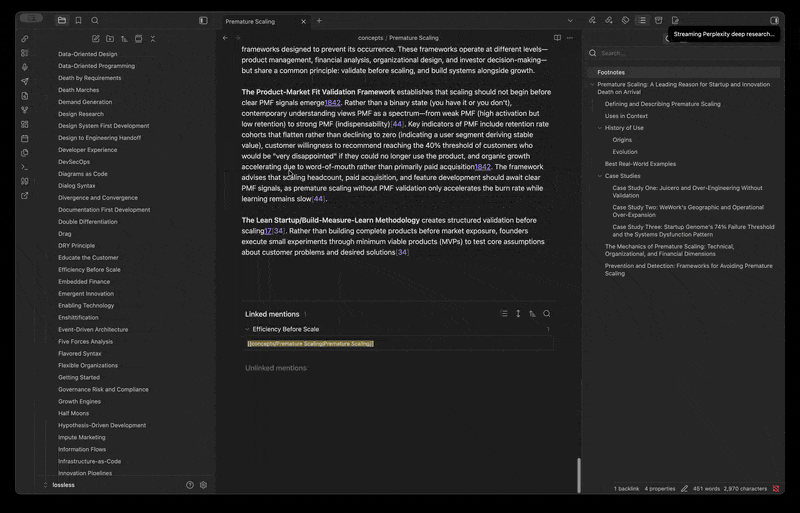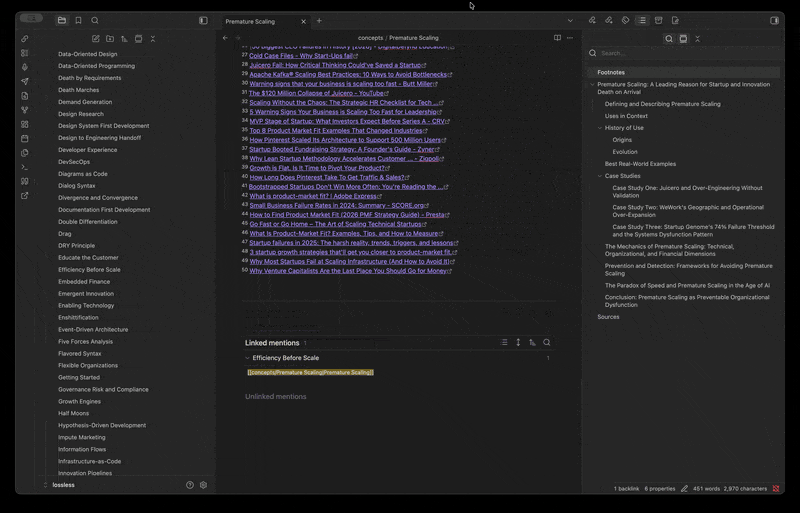
Why Care?
If you keep a knowledge vault — concepts, tools, vocabulary, source profiles — most of it never gets filled in. You stub a folder for every concept you encounter, every tool you evaluate, every term worth defining, intending to come back and write each one up properly. You never do.
Our Example: There are 1,600 nearly-empty profile files in your Toolkit folder, hundreds of concepts waiting in your concepts folder, vocabulary entries sitting at title-only. Filling them in one file at a time is untenable, even one at a time with LLM output. A generic "summarize this for me" pass on each file produces homogenous slop with no citations and no editorial point of view.
Perplexed 0.1.1 is the release where the plugin stops being a per-query research modal and starts being a per-directory content workflow. You drop one template into a directory describing how its files should be filled in — what to research, what tone to take, what frontmatter to stamp, where the sources footer goes — and the plugin streams source-cited content into every file in that directory (or a single file, or a folder batch), using Perplexity for research and routing the output through a citation pipeline that's already compatible with Cite-Wide's hex-citation format.
Hats off to Text Generator for the inspiration for this feature. Yes, we used Text Generator; though it was awesome, it wasn't quite the way we needed it to be.
The same release adds Claude as the third research provider alongside Perplexity and Perplexica, a first-run seeder that drops the four shipped templates into your vault automatically so you can see the format before writing your own, and Marketplace availability through the new community.obsidian.md portal.
What's New?
Per-directory content generation via templates
Drop a template file into a directory — one of the four shipped templates, or your own — and Perplexed can generate source-cited content for every file in that directory in one pass. The template uses a small cf / cft codefence DSL to describe what to research, what frontmatter to stamp, and how to format the output. Each cf block is a content-generation instruction; each cft block is a template that gets interpolated against frontmatter values in the target file.
The runtime applies the template via Perplexity research, streams writes back into the file as the response arrives (you see it appear in real time, not as a final block at the end), and stamps run-tracking frontmatter (cf_last_run timestamp + cf_last_run_model) so you can query for stale files later — "which concept profiles haven't been refreshed since April?" becomes a single Dataview query.
Four shipped templates cover the most common knowledge-vault shapes:
| Template | Lives in | What it fills |
|---|---|---|
| concept-profile | concepts/ (or wherever you keep them) |
A concept explainer with definition, history, examples, and editorial stance — biased against attributing the concept to tech giants when it actually originated in research labs, startup founder interviews, or earlier papers |
| vocabulary-profile | Vocabulary/** |
An innovation-consultant lens definition of a term — what it means, why it matters, what it's often confused with |
| source-profile | Sources/ or Citations/ |
A source dossier that handles articles, books (via Google Books URL harvesting), and other source types via nested type-handling |
| toolkit-profile | Tooling/** |
A profile for a tool, library, or service the vault tracks |
Each runs as one file at a time, a folder batch that walks every file in a directory, or in append-below mode that writes underneath existing content rather than replacing it.
Anti-incumbent editorial stance baked into the prompts
The concept-profile template's system prompt explicitly instructs the model to treat tech giants (Google, Microsoft, Meta, OpenAI, Amazon, Apple) as adopters and popularizers — not originators — of concepts. The "Examples" section caps how many big-tech examples are allowed, and the prompts actively prefer startups, research-lab papers, and founder-interview attribution over the easy "X was invented by [big company]" framing that vanilla LLM output defaults to.
This is editorial discipline you can read in the prompt, not a hand-wave. If a concept genuinely originated at a tech giant, the prompt allows it; what it pushes back against is the laziness of always attributing.
Auto-seeding — templates arrive with the plugin
Install Perplexed, open Obsidian, and the plugin's first-run seeder drops the four shipped templates plus a README explaining the format into your vault automatically. You can see the template format before writing your own, modify the shipped ones to taste, or ignore them entirely — the README is always re-ensured on plugin load (so updates land), but the templates are treated as user-managed after first deployment (so your edits aren't overwritten).
Claude joins as the third research provider
Anthropic's Claude is now wired in alongside Perplexity and Perplexica via a dedicated Ask Claude modal. Uses the official Anthropic SDK with server-side web_search enabled, adaptive thinking, response streaming, and a two-pass citation extraction pipeline that handles both per-claim text-block citations (the structured citation objects Claude attaches to specific sentences) and bare web_search_tool_result fallbacks (the looser citation form Claude sometimes returns when it can't anchor a citation to a specific claim).
So your provider choices for any research command are now:
| Provider | Endpoint | Cost | Best for |
|---|---|---|---|
| Perplexity | api.perplexity.ai | Paid | Source-cited research with consistent citation formatting |
| Anthropic Claude | api.anthropic.com | Paid | Longer-form reasoning with web_search and adaptive thinking |
| Perplexica / Vane | localhost:3030 (self-hosted) | Free | Privacy-sensitive research; runs entirely on your machine |
| LM Studio | localhost:1234 (local) | Free | Local-only inference, no network |
Wide, consistent modals across all three Ask commands
The Ask Perplexity, Ask Claude, and Ask Perplexica modals now share a redesigned, wide, visually consistent UI. The wide-modal CSS technique (the modalEl rather than contentEl styling trick) means there's actually room for the streaming response to land in a readable column instead of a 480px-wide squeeze.
Better Find Images — anchored to your selection, with strict domain filtering
The existing Find Images for Selection command now does selection-anchored image discovery with paragraph-level placement. Search results land near the text they relate to, not appended at the end of the document. A strict domain filter (search_domain_filter) rejects off-domain results so when you ask for images from example.com you get images from example.com, not whatever the image-search backend would have surfaced absent the filter.
Sources Footer compatible with Cite-Wide
When the directory-template runtime writes a sources section, it emits the canonical [N]: reference-definition format (per the Lossless Citation Spec) so that running Cite-Wide's Convert Numeric Citations to Hex afterwards transforms them directly into stable [^hex] markers. The two plugins now compose cleanly: Perplexed generates, Cite-Wide canonicalizes.
A separator (***) is also emitted above the # Sources heading with proper blank-line spacing, so the footer reads as a deliberate section rather than appended noise.
Sonar instructed to emit inline citations
When using Perplexity's Sonar models, the system prompt now explicitly instructs the model to emit inline [N] citation markers in the body of the response (not just in a trailing references list). Combined with the cite-wide-compatible sources footer above, the post-generation conversion to [^hex] markers is one command.
Installable from the new Obsidian community portal
Obsidian retired the long-running PR-based submission queue (obsidianmd/obsidian-releases) in favor of a hosted portal at community.obsidian.md. Perplexed 0.1.1 is the first version published through the new portal — reachable from inside Obsidian via Settings → Community Plugins → Browse → search "Perplexed".
Sibling Lossless plugins shipped through the same portal-discipline pass: image-gin 0.2.2 and cite-wide 0.2.0.
Under the Hood
Each substantive piece of work shipped in 0.1.1 has its own per-day changelog under changelog/:
| Date | Topic | Per-day changelog |
|---|---|---|
| 2026-04-30 | Claude provider integration — Anthropic SDK + Ask Claude modal + web_search + adaptive thinking + streaming + two-pass citation extraction (per-claim text-block citations + bare web_search_tool_result fallbacks) | 2026-04-30_01.md |
| 2026-05-01 → 2026-05-02 | UX pass — modal redesign + wide-modal CSS unlock; consistent UI across Ask Perplexity, Ask Claude, and Ask Perplexica modals | 2026-05-01_01.md |
| 2026-05-02 | Maintenance pass — dependency refresh resolving Dependabot flags; streaming-citations bug fix | 2026-05-02_01.md |
| 2026-05-09 → 2026-05-10 | Directory Templates paradigm — the headline feature. cf / cft codefence DSL, four shipped templates (concept / vocabulary / source / toolkit), streaming + cleanup pipeline w... |
Perplexed 0.1.0 — first release
Perplexed 0.1.0 — first release
Perplexed brings source-cited AI research directly into your Obsidian
vault. Ask a question from a command, get a streamed answer written into
the active note at the cursor — followed by a ### Citations section of
real, clickable references you can audit and reuse.
This is the first tagged release and the version submitted to the
Obsidian community plugin directory. Everything below describes what
ships in the box.
What's in the box
Four AI providers, one workflow
| Provider | What it's for | Where it runs | Account / key |
|---|---|---|---|
| Perplexity | Web-grounded research with native citations and recency filters | Cloud (api.perplexity.ai) | Account + paid API key |
| Anthropic Claude | Frontier-model research with server-side web_search and adaptive thinking |
Cloud (api.anthropic.com) | Account + paid API key |
| Perplexica / Vane | Self-hosted, source-grounded answers via your own SearXNG-backed search | Local — you install ItzCrazyKns/Vane | None (self-hosted) |
| LM Studio | Fully local LLM responses, no internet required | Local (LM Studio app) | None (local only) |
The plugin only contacts a remote service when you invoke its
command. Nothing is sent automatically. No telemetry, no auto-updates
(Obsidian handles plugin updates through the community directory), no
vault content shipped anywhere else.
Streaming responses, written into your note
Answers stream token-by-token into the active note at the cursor — so
long-running research (Claude with web search + thinking, or Perplexity
with sonar-deep-research) shows progress instead of hanging on a
spinner. A 90-second idle timeout surfaces a clear error instead of
silently truncating if the upstream stalls.
Citations that follow the Lossless Citation Spec
Every provider that returns sources renders them as a ### Citations
block of single-line reference definitions:
### Citations
[1]: [What is GRC (Governance, Risk and Compliance) — Metricstream](https://www.metricstream.com/learn/what-is-grc.html). Published: 2024-05-01 | Updated: 2024-12-13
[2]: [Governance, risk and compliance (GRC): Definitions and resources](https://www.diligent.com/resources/guides/grc). Published: 2025-05-27 | Updated: 2025-06-16Claude responses additionally carry per-claim quoted source text:
[3]: [The Title of the Source](https://example.com/path). > The verbatim cited text from the source.Numeric identifiers are deliberate — they keep markup homogeneous across
providers, and downstream tooling like
cite-wide can promote
them to stable hex codes in a later pass.
Provider-specific knobs, surfaced where you choose them
Every "Ask " command opens a modal with the relevant controls
for that provider — and a live tagline under each dropdown that
explains what the option actually does, so you don't have to consult
external docs at decision time.
- Ask Perplexity — model (
sonar-pro,sonar-small,
sonar-deep-research, llama variants), recency filter (day → year),
citations / images / related questions toggles, streaming toggle. - Ask Claude — model (Opus 4.7, Opus 4.6, Sonnet 4.6, Haiku 4.5),
effort (low→max), web search toggle, adaptive thinking toggle,
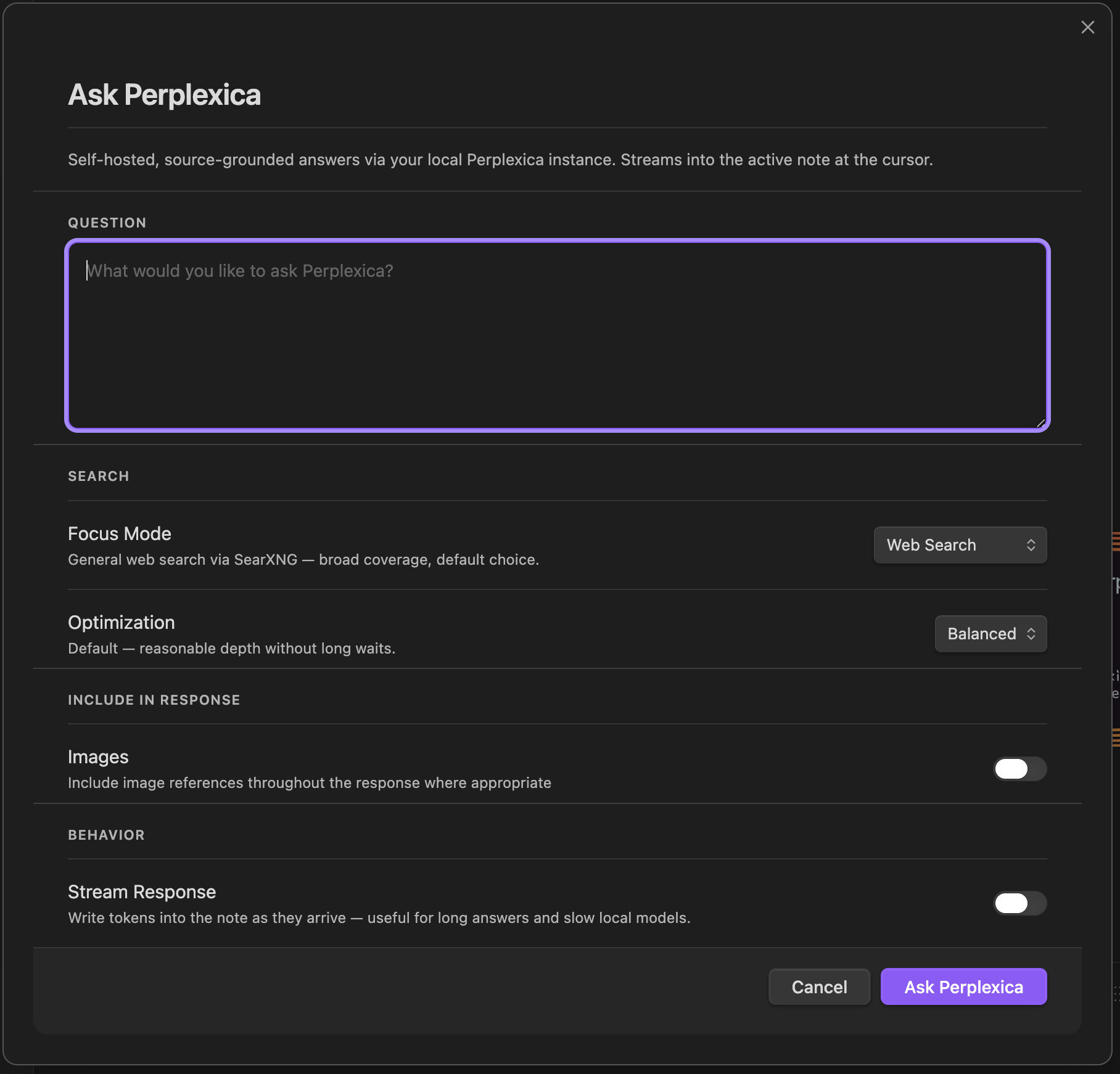
streaming toggle. - Ask Perplexica / Vane — focus mode (Web / Academic / Writing /
Wolfram / YouTube / Reddit), optimization (Speed / Balanced /
Quality), images toggle, streaming toggle. - Ask LM Studio — model picker, system prompt, temperature, max
tokens.
Text enhancement from selection
Highlight a passage, run Enhance Selected Text with Perplexity, and
get a richer, source-cited rewrite. Choose to replace the selection,
insert below it, or preview before applying.
Configurable endpoints
Every provider's endpoint is user-configurable in settings — point
Perplexica at your custom port, swap LM Studio's path, or override the
Perplexity URL if you're testing against a proxy.
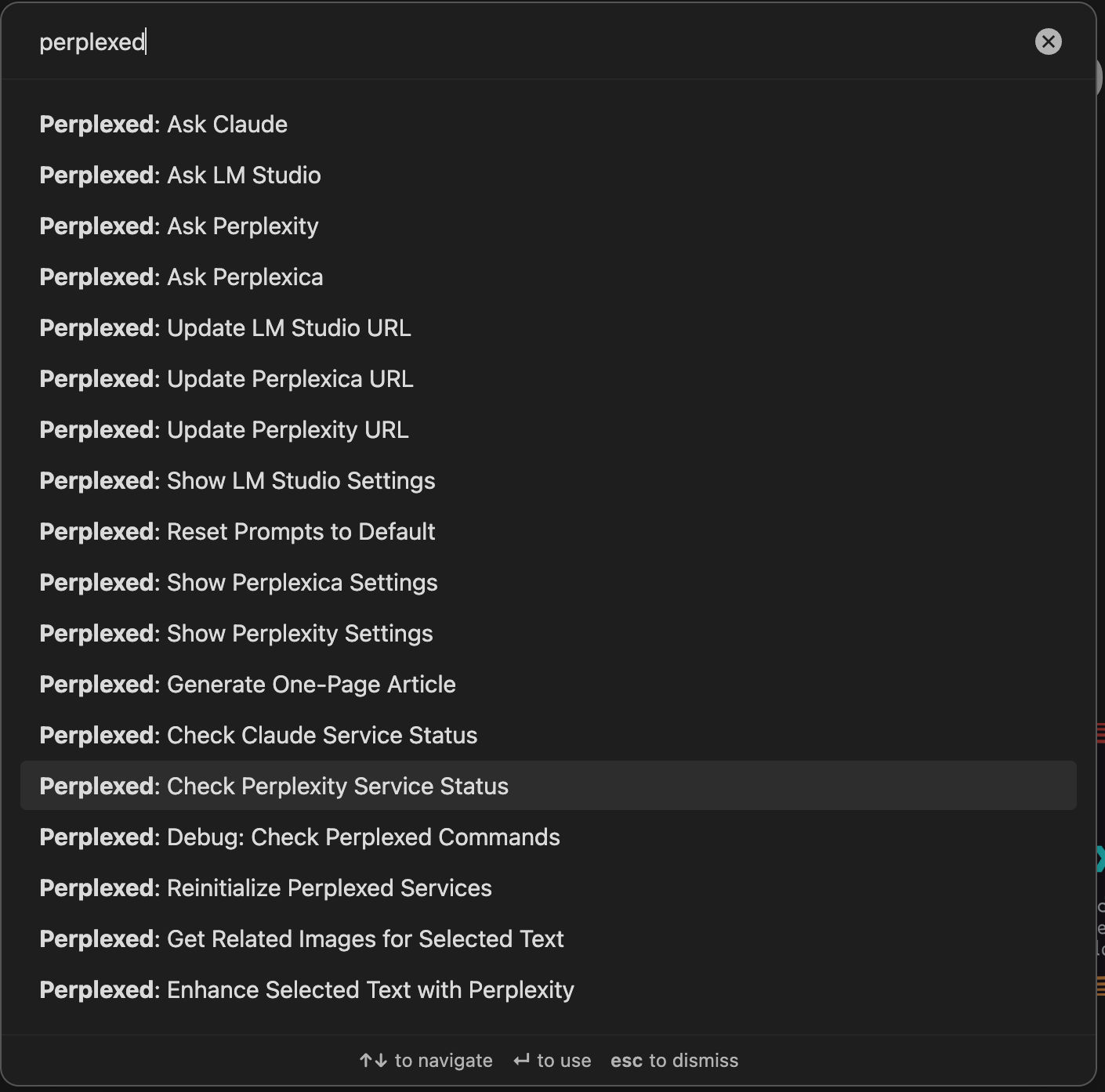
Commands at a glance
| Command | Provider |
|---|---|
| Ask Perplexity | Perplexity |
| Enhance Selected Text with Perplexity | Perplexity |
| Ask Claude | Claude |
| Check Claude Service Status | Claude (diagnostic) |
| Ask Perplexica / Vane | Perplexica / Vane |
| Ask LM Studio | LM Studio |
| Update / Show settings (per provider) | All |
Bind any of them to a hotkey from Obsidian → Settings → Hotkeys.
Installation
For users
From the Obsidian community directory (recommended, once approved):
Settings → Community Plugins → Browse → search "Perplexed" → Install →
Enable.
Manually from this release: download main.js, manifest.json,
and styles.css into <vault>/.obsidian/plugins/perplexed/, then
enable the plugin in Settings → Community Plugins.
After installation, open Settings → Community Plugins → Perplexed
to add API keys for the providers you intend to use. Local providers
(Perplexica / Vane, LM Studio) need their respective servers running —
the plugin doesn't bundle them.
For contributors
Clone the repo into wherever you keep your Obsidian plugin source —
not directly into a vault's .obsidian/plugins/ directory:
git clone https://github.com/lossless-group/perplexed-plugin.git
cd perplexed-plugin
pnpm install
pnpm build # one-shot production build
# or
pnpm dev # watch modeThen symlink your dev checkout into the Obsidian vault you want to test
in. If this is your first Obsidian plugin, the convention is to keep
your source tree somewhere like ~/code/obsidian-plugins/<name>/ and
symlink it into each vault you want to load it from:
macOS / Linux
ln -s /absolute/path/to/perplexed-obsidian-plugin \
/absolute/path/to/your-vault/.obsidian/plugins/perplexedWindows (PowerShell as admin)
New-Item -ItemType SymbolicLink `
-Path "C:\path\to\your-vault\.obsidian\plugins\perplexed" `
-Target "C:\path\to\perplexed-obsidian-plugin"After the symlink, enable the plugin in Settings → Community Plugins
(disable Safe Mode first if it's on). pnpm dev rebuilds on save;
reload Obsidian (Cmd/Ctrl+R in the dev console) to pick up changes.
PRs welcome — see the Developer Onboarding section of the README for
architecture notes and the changelog/ directory for recent design
decisions and their rationales.
A note on the "Perplexica / Vane" naming
The self-hosted upstream this plugin talks to was renamed from
Perplexica to Vane by its maintainer (ItzCrazyKns) on
2026-03-09. The old GitHub URL still redirects, the local API surface
(/api/search, focus modes, optimization modes) is unchanged, and a
separate hosted product at perplexica.io continues to exist under the
Perplexica name. The plugin uses the dual label "Perplexica / Vane" in
user-facing surfaces so users coming from either name can find it.
Compatibility & requirements
- Obsidian: ≥ 0.15.0
- Platform: Desktop only (
isDesktopOnly: true— Electronfetch
and the Anthropic SDK both require the desktop runtime). - Node / dev: Node 18+ if you're building from source, with
pnpm.
Known limitations
- Claude's
web_searchtool is set toauto, which means the model
may answer from training knowledge on questions inside its cutoff —
producing a correct answer with no citations. If citations are
required, prefer Perplexity for now. - Several legacy modals (URL update, article generator) still use the
default narrow Obsidian width; the wide-modal pattern landed for the
three primary "Ask" modals plus LM Studio and text-enhancement, and
the rest will follow. - Streaming pipeline now has a 90-second idle timeout to surface stalls
as errors rather than truncating silently. If you're running
sonar-deep-researchagainst a slow connection, that ceiling may
need to be raised — file an issue if you hit it.
Credits
Built by The Lossless Group. Thanks to
Anthropic, Perplexity, ItzCrazyKns (Vane / Perplexica), and the LM
Studio team for the underlying providers, and to the Obsidian community
for the plugin platform that makes this kind of integration possible.
Issues and feedback: https://github.com/lossless-group/perplexed-plugin/issues