- 본 Repository에는 취업준비를 하면서 공부한 자료구조/알고리즘의 개념 및 실습, 코딩테스트 풀이 등을 담았습니다. 아래 링크 및 내용은 지속적 업데이트 예정입니다.

- 입력값에 따른 연산에 걸리는 시간을 변수에 따라 표기
- 간단한 인덱싱
function O_1_algorithm(arr, index) {
return arr[index];
}
let arr = [1, 2, 3, 4, 5];
let index = 1;
let result = O_1_algorithm(arr, index);
console.log(result); // 2
- 시간복잡도가 linear하게 증가
- range 길이가 n개인 for문이 대표적
- 업다운 게임을 생각
- BFS 알고리즘이 대표적
- 이중 for문
- 재귀함수가 대표적(피보나찌)
function fibonacci(n) {
if (n <= 1) {
return 1;
}
return fibonacci(n - 1) + fibonacci(n - 2);
}
하나의 루프를 사용하여 단일 요소 집합을 반복 하는 경우 : O (n) 컬렉션의 절반 이상 을 반복 하는 경우 : O (n / 2) -> O (n) 두 개의 다른 루프를 사용하여 두 개의 개별 콜렉션을 반복 할 경우 : O (n + m) -> O (n) 두 개의 중첩 루프를 사용하여 단일 컬렉션을 반복하는 경우 : O (n²) 두 개의 중첩 루프를 사용하여 두 개의 다른 콜렉션을 반복 할 경우 : O (n * m) -> O (n²) 컬렉션 정렬을 사용하는 경우 : O(n*log(n))


[https://blog.chulgil.me/algorithm/]

- key 값들이 hash table의 각 값에 mapping 됨
- 이러한 mapping은
hash function에 의함 - hash table의 각 칸들을 hash bucket이라고 함
[https://medium.com/@songjaeyoung92/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-javascript-hash-table-%EC%9D%B4%EB%9E%80-5f5345623dab]
- 같은 value(hash bucket)에 mapping될 경우, 이를 collision(충돌)이라고 함. 하나의 경우 bucket을 연달아 저장하는 방법이 있음

구현 및 코딩?🤔
- python의 dictionary 자료형을 이용하면 각 key와 value값을 상수시간(O(n))에 접근 가능
- value의 자료형에 따라 defaultdict를 활용하면 직관적인(짧은)코딩 가능
- value 얻을 때 indexing
[index]보다는dict.get메소드를 쓰는것이 에러를 방지 (예외처리 용이)
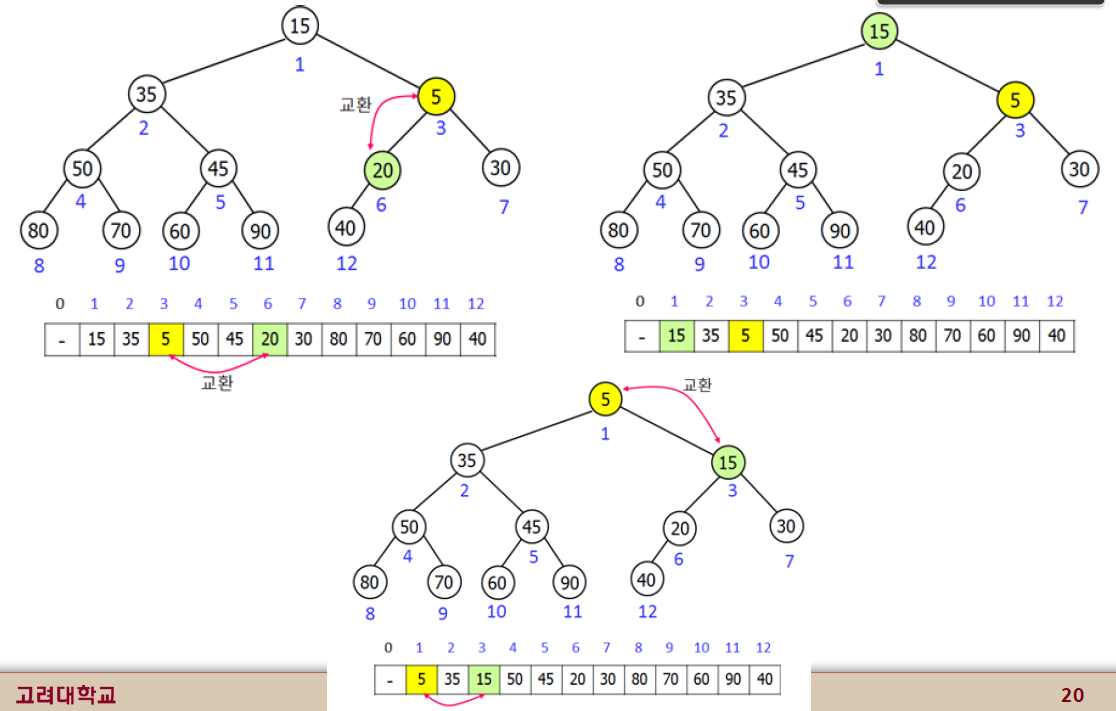
- binary tree 를 가정
- 최소힙 또는 최대힙이 있고, 아래 예시는 최소힙을 가정하고 든 예시
- 시간복잡도가 log(n) 으로 우선순위 큐와 같은 자료구조보다 효율적인 알고리즘 구현 가능
- 고려대학교 뇌영상분석연구실 교육자료 참고.


import heapq as hp
x=[3,2,1,4,5]
hp.heapify(x) # heap으로 만듦
print(x)
>> [1, 2, 3, 4, 5]
hp.heappush(x,3) # item 삽입
print(x)
>> [1, 2, 3, 4, 5, 3] # binary tree의 마지막 노드에 추가됨
hp.heappop(x) # 최솟값 삭제 delete_min
print(x)
>> [2, 3, 3, 4, 5]
hp.heappushpop(x,1) # item 삽입 후 delete_min 수행
print(x)
>> [2, 3, 3, 4, 5] # 1이 최소였기에 그낭 튀어나왔음
hp.heapreplace(x,1) #delete 먼저 한다음 item 삽입
print(x)
>> [1, 3, 3, 4, 5] # 1로 대체되었다 (replace)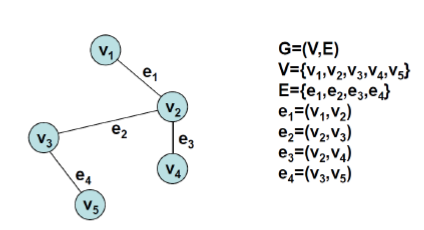
-
$$V$$ : Vertices( or Nodes) -
$$E$$ : edges (connect vertex and vertex)
위와 같이


- edge는 vertice의 쌍으로 표현됨 (a,b)
- edge는 방향 또는 weight를 가질 수 있음
- degree 는 vertice에 개입된 edge의 수를 표현
- loop : 같은 vertice에 연결된 edge

- 그래프간 edge관계를 행렬로 나타낸 것
- 방향이 없는 그래프에서는 대칭행렬의 꼴을 보임

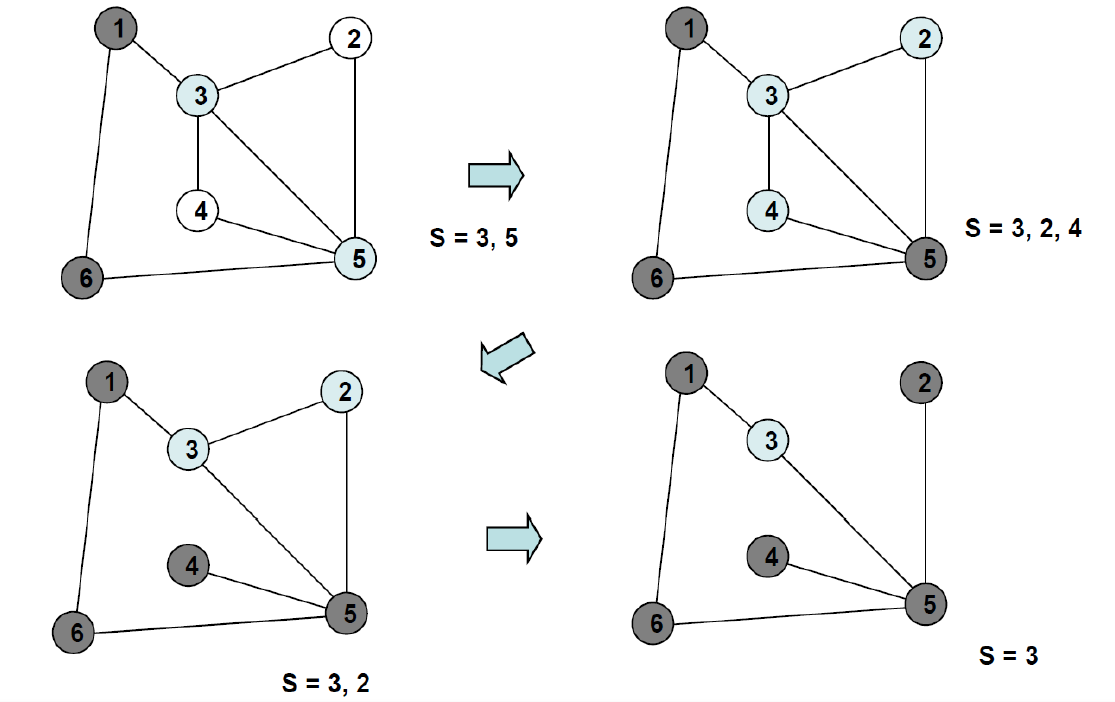
- 너비우선 탐색
- queue의 자료구조 활용
- 방문한 노드들을 차례로 저장한 후 꺼낼 수 있는 자료 구조인 큐(Queue)를 사용함
- 즉 선입선출(FIFO) 원칙으로 탐색
- 최단경로 문제에 적합
- 깊이 우선 탐색
- stack 자료구조 또는 Recursive algorithm으로 구현
- 경로의 특징을 저장해둬야 하는 문제에 적합
- 그래프의 모든 정점을 방문하는 것이 주요한 문제라면 어느 것을 쓰든 노상관
- 검색 대상 그래프가 정말 크다면 DFS를 고려
- 검색대상의 규모가 크지 않고, 검색 시작 지점으로부터 원하는 대상이 별로 멀지 않다면 BFS
- sorting1 - bubble sort, selection sort, insertion sort (개념 및python 실습)
- sorting2 - mergesort, quicksort, heapsort (개념 및 python 실습)
- sorting3 - counting, radix, topological
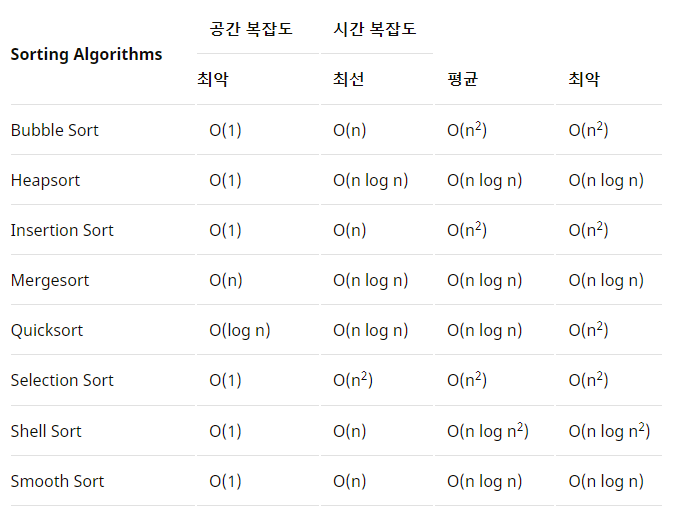
- 정렬 알고리즘 시간복잡도 비교
유념할 점😎 최솟값을 구하려면 맨 처음에는 최대 값을 골라서 설정해주고 비교해나가면서 설정해주는 방식이 좋다. dp 리스트를 정의할 때 index 값에 매핑되는 그 값부터 제대로 정의하는게 핵심이다. 그러고 나면 문제의 실마리가 보인다.
- 함수 호출이 너무 많다
- 동일한 parameter를 갖는 함수 호출이 중복되어 비효율적
- 정보를 미리 저장해두고 작은 문제부터 하나하나씩 해결해가면 어떨까?
2를 8번 더하면 16이다. -> 2를 9번 더할 때는 다시 더하지 말고 2를 8번 더한 것에 2를 더하면 돼!

- Recursion : top-down으로 task의 맨 위부터 호출
- DP : sub instance인 F(0)부터 그 결과를 memoization에 저장 (bottom-up)
위 그림을 코드로 구현해 봅시다.
#recursive
def fibonacci(x):
if x==0:
return 0
if x==1:
return 1
return fibonacci(x-1)+fibonacci(x-2)
fibonacci(8)
>>> 21
#dp
def fibonacci_dp(x):
dic = {}
dic[0] = 0
dic[1] = 1
for itr in range(2, x+1):
dic[itr] = dic[itr-2] + dic[itr-1]
return dic[x]
fibonacci_dp(8)
>>> 21
- dp를 사용하면 recursion과 달리 매 0,1 결과값으로 그 다음 스텝 값을 계속 저장한다.
- 여기서는 memoization table로 dictionary 자료구조를 이용했다.
- 단계별로 현 상황에서의 최적해를 선택.
언제 적용해야 하나?
- 최종해의 최적성에 영향을 미치지 않는다는 확신이 있어야 함.
- 공통적으로 경로 찾기 문제에 적합.
- BFS : queue로 구현
- 최단경로에 적합
- DFS : 재귀나 stack으로 구현
- 경로의 특징을 저장해둘 때 적합