I build production-grade agentic AI systems — evidence-backed, measurable, and trusted in enterprise workflows.

![]()




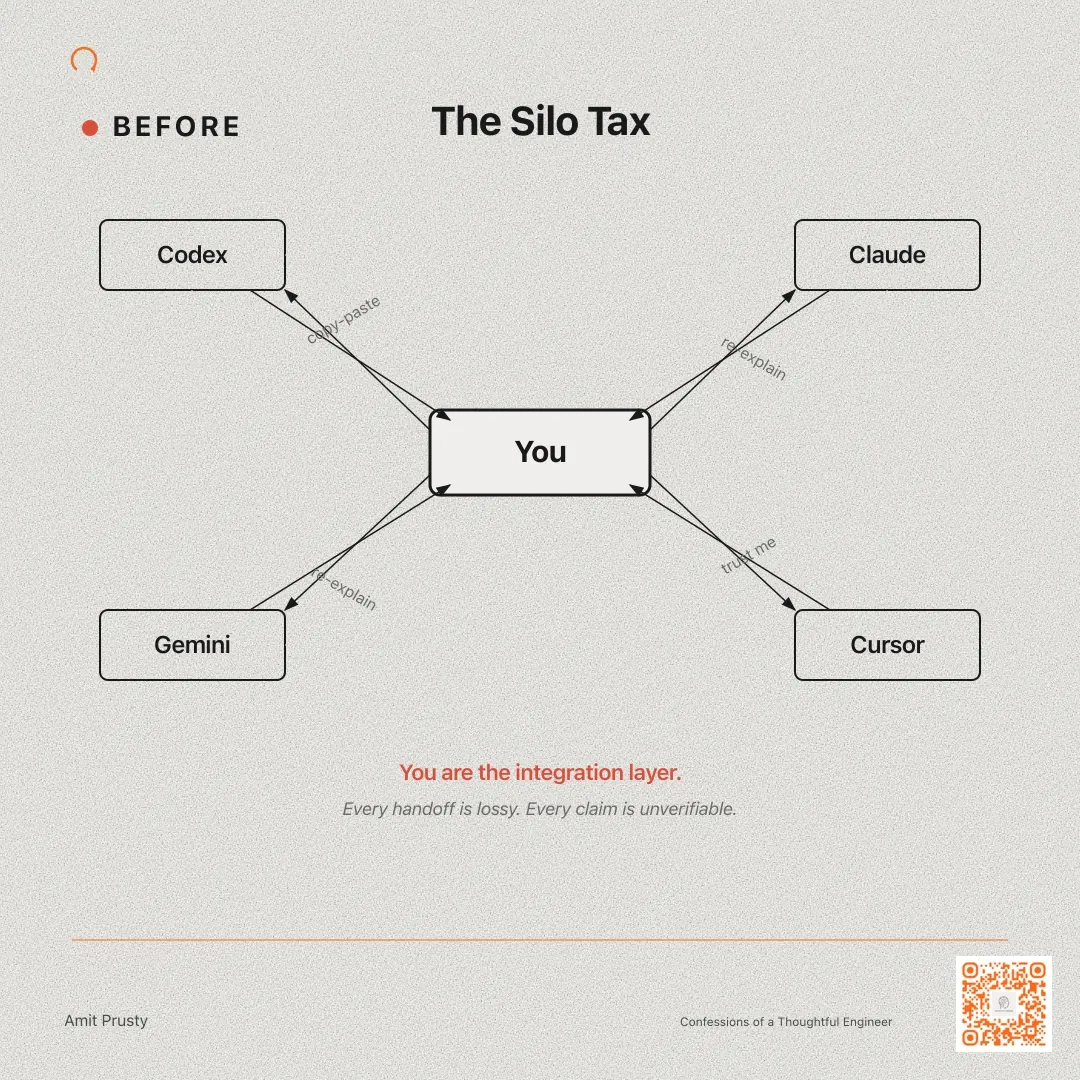
Let your AI agents talk about each other.
Local-first CLI for evidence-backed cross-agent coordination across Codex, Claude, Gemini, and Cursor. One agent reads another's session with citations and structured evidence — no orchestrator required.
- Dual implementation: Node.js + Rust with conformance-tested parity
- Session reads, diffs, comparisons, agent messaging, secret redaction
- Context Pack: 5-doc agent-first repo briefing that eliminates cold-start re-reads
- Zero npm prod dependencies, works offline, nothing leaves your machine
| agent-chorus | CrewAI / AutoGen | ccswarm / claude-squad | |
|---|---|---|---|
| Approach | Read-only evidence layer | Full orchestration framework | Parallel agent spawning |
| Agents | Codex, Claude, Gemini, Cursor | Provider-specific | Usually Claude-only |
| Dependencies | Zero npm prod deps | Heavy Python/TS stack | Moderate |
| Cold-start solution | Context Pack | None | None |
Repo: cote-star/agent-chorus


Diagnose. Prescribe. Refuse.
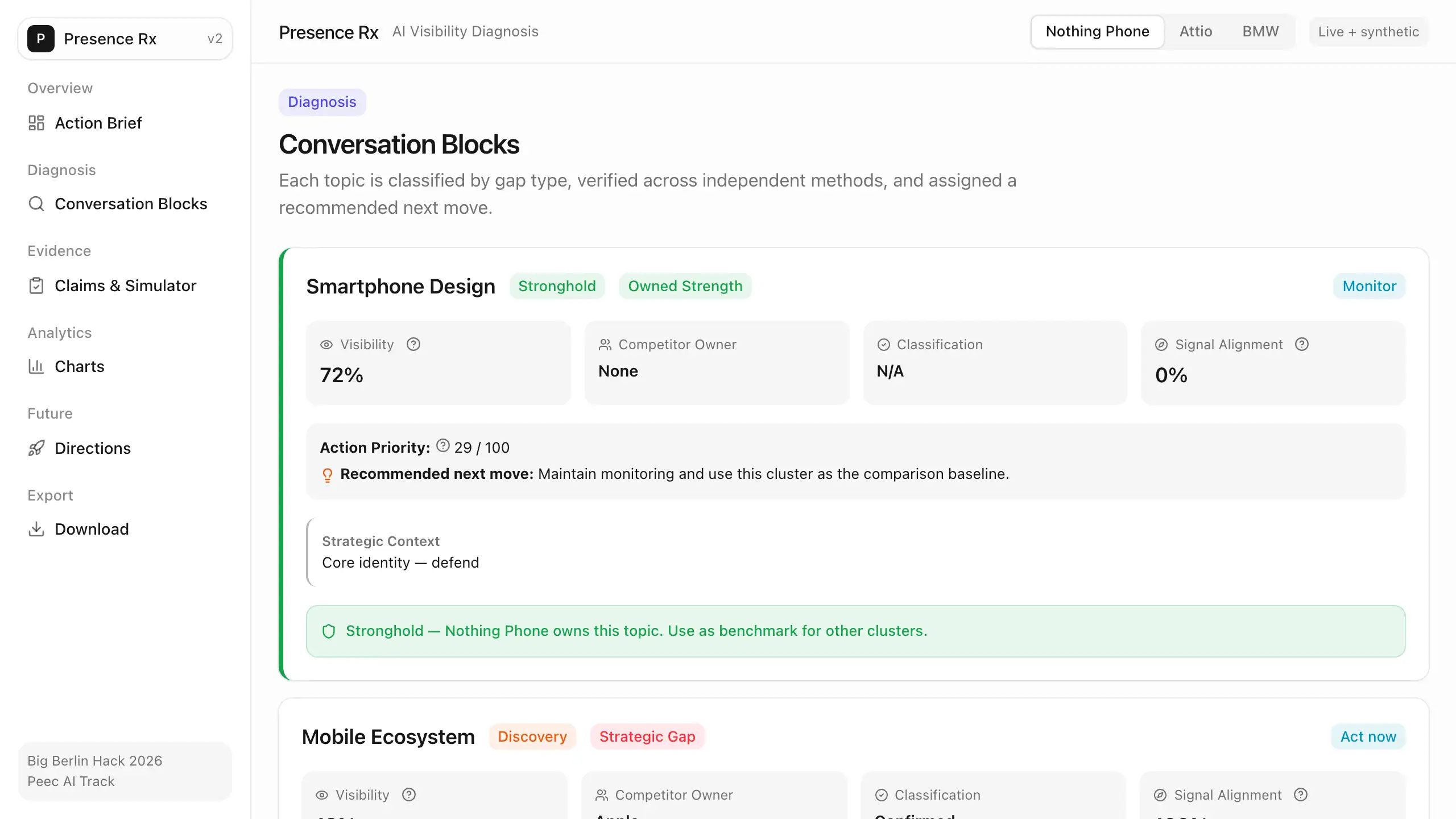
AI-powered brand diagnostics that finds your blind spots in AI-generated answers, classifies each gap, and refuses to let you overclaim. Built for the Peec AI track at Big Berlin Hack 2026.
- 6-axis blind-spot model: topic, channel, engine, geography, authority, evidence
- Gap-type classifier distinguishes perception, discovery, and attention gaps — each gets a different fix
- Blocked-claims register with safe rewrites: the system kills overclaims with receipts
- 189 passing tests, 3 brands (Nothing Phone, Attio, BMW), full proof chain at every step
- Pipeline: Peec AI + Gemini + Tavily → Python backend + Next.js interactive dashboard
Repo: cote-star/presence-rx
![]()


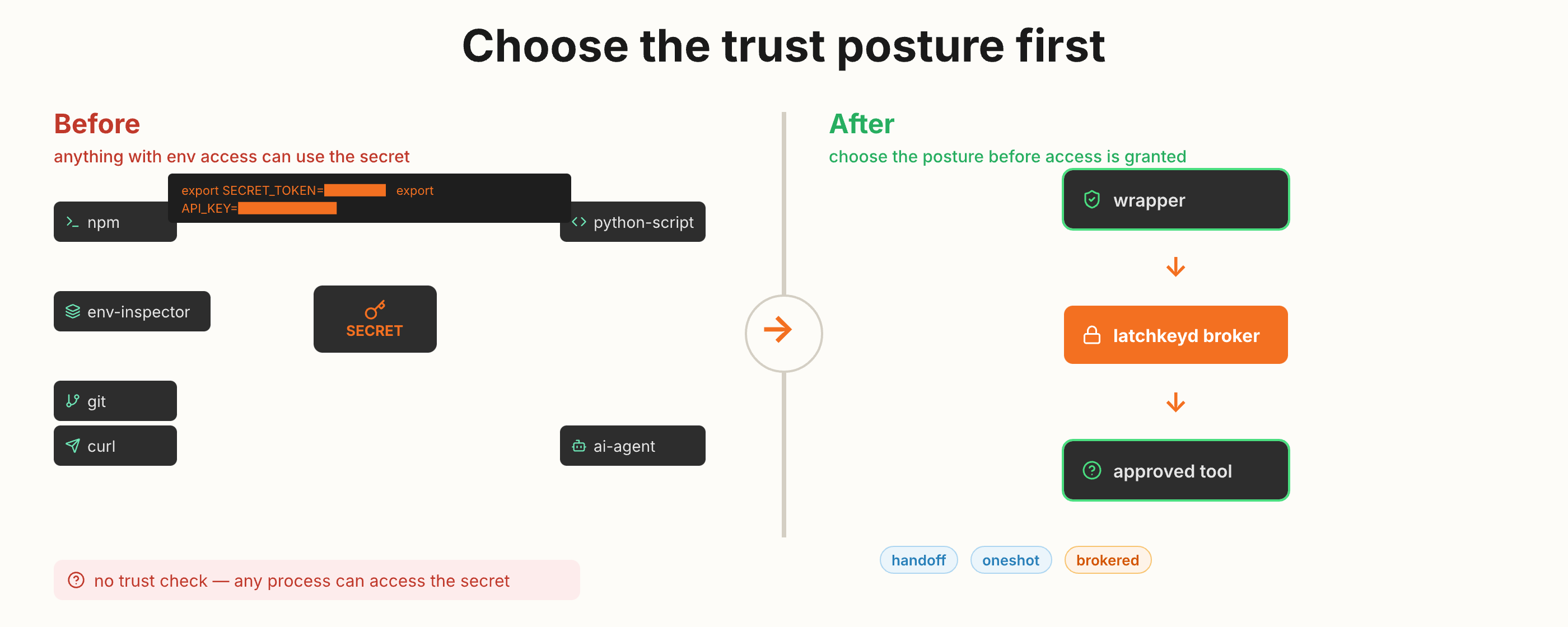
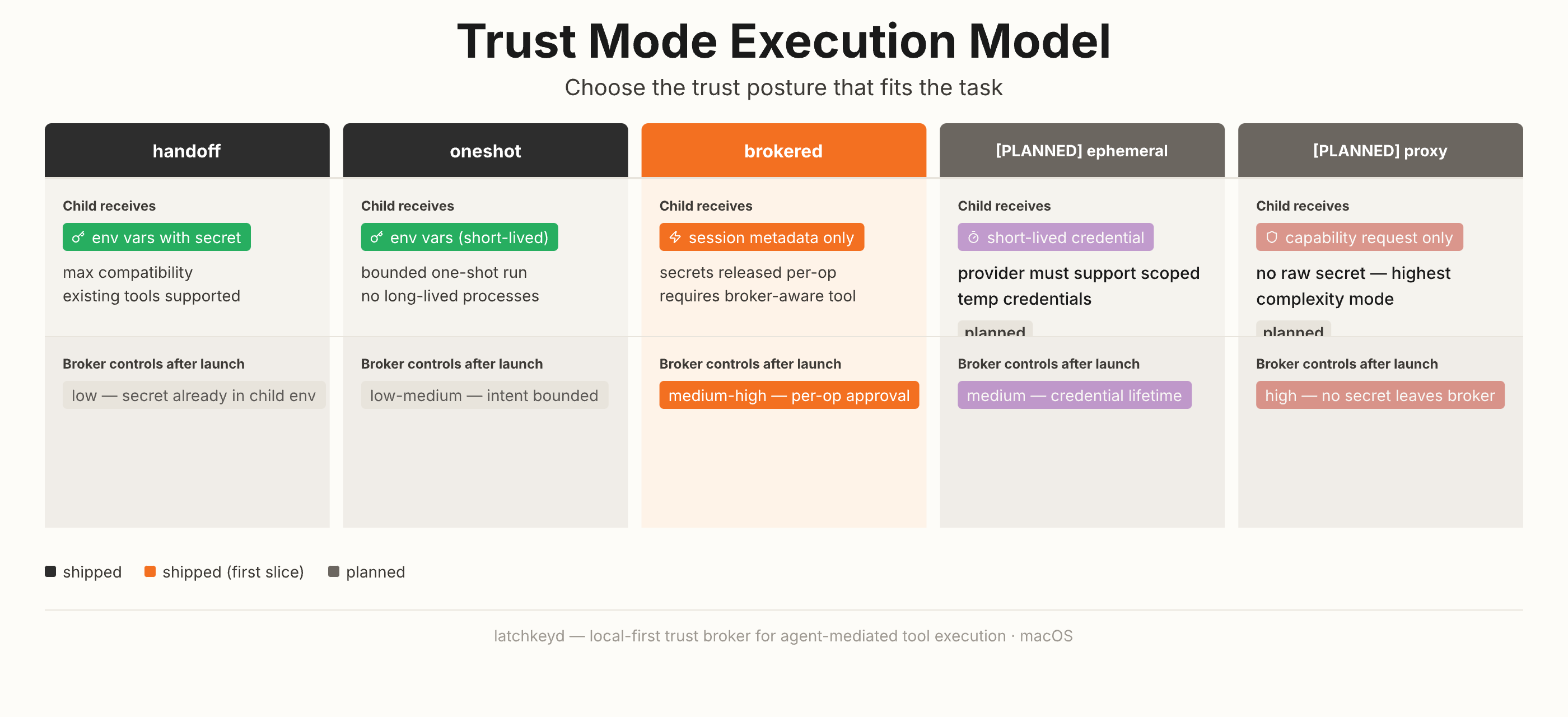
Choose the trust posture before a local tool gets credential-backed access.
macOS-first local trust broker for agent-mediated tool execution. Secrets stay local, wrappers and binaries are trust-pinned, and you choose the trust mode per task.
- Three shipped modes: handoff (env injection), oneshot (bounded run), brokered (per-operation request)
- Swift 6.0, macOS Keychain-backed, JSONL audit trail with enforced preflight
- Fail-closed on drift, hijack, or bypass — defense in depth, not "secure agents solved"
Repo: cote-star/latchkeyd
An experiment-backed investigation into how AI agents navigate large codebases — and how static context packs change the outcome.
- 78+ graded experiments across 3 repos, 3 agent families
- Headline: 88% structural correctness (was 50%), 70% fewer files read, 65% fewer tokens
- Interactive results dashboard and evidence maps
- Blog draft + research paper in progress
Repo: cote-star/agent-recall
- Production multi-agent systems and coordination reliability
- Context engineering — reducing the cold-start and silo taxes
- AI-powered brand intelligence and evidence-graded analytics
- LLM/VLM engineering with research-to-production translation
- Fine-tuning, structured generation, and inference optimization
- LLMOps, evaluation, and governance for enterprise deployment
- Local-first agent security and trust infrastructure
Practical field notes on enterprise AI reliability and agent systems:
- The Silo Tax — why multi-agent workflows break
- Why Agents Don't Fail Fast — they fail slow
More at Confessions of a Thoughtful Engineer
- Evidence over assumptions
- Reliability over demo polish
- Measurable outcomes over vague AI claims
- Simplicity first; orchestration only when needed