{kind=link}
팀명 : 1818
팀장 : 김호연
팀원 : 곽세경, 박현우, 최미리, 최정원
주제 : AI기반 공공전화 연결 서비스 "1818"
-
‘콜 포 코드(Call for Code)’ 글로벌 챌린지는 인공 지능, 블록체인, 클라우드, IoT 등의 정보통신기술(ICT)을 활용하여 가장 심각한 문제로 대두된 글로벌 이슈의 해법을 찾는 전 세계 개발자 대회입니다.
-
3년째를 맞이하는 2020년, 코로나19와 기후변화의 솔루션을 만드는 ‘2020 콜 포 코드 한국 해커톤’에 참가할 능력 있는 개발자와 기획자, 디자이너를 찾습니다.
-
함께 프로젝트를 수행할 팀원과 전문가 멘토를 만나고 코로나19, 기후변화에 대한 온라인 교육을 통해 사회문제 전문가, ICT 전문가와 어떤 사회문제를 어떻게 ICT로 풀어나갈 수 있을지 함께 이야기 나눠봅니다.
-
그리고 이를 통해 사회가 필요로 하는 상용화 가능한 서비스를 직접 만들어보세요. 당신이 만든 코드가 세상을 구할 수 있는 특별한 기회, 지금 도전하세요!
-
Korea Hackathon은 IBM Korea, 서울시, 서울혁신파크, 서울이노베이션팹랩이 함께합니다.
예시 : 긴급 커뮤니케이션 시스템, 원격 교육 지원, 지역 사회 협력 구축, 기부금 플랫폼 등
예시 : 순환경제 지원 플랫폼, 재난 복원을 위한 서비스, 에너지 / 물 지속 가능성 지원 등
| Step | Date | Property |
|---|---|---|
| 참가 신청 및 아이디어 제출 | 2020.04.23 ~ 05.13 | 참가 신청 5인 이하의 팀 또는 개인 구성 간단한 아이디어 접수 |
| 2020.05.12 | 최종 참가자 발표 * 이후 세부 일정 및 진행방식 개별 안내 예정 | |
| 온라인 교육 세션 및 한국 해커톤 진행 | 2020.05.14 ~ 05.29 | 3회 온라인 교육 세션 및 개인 참여자 팀 구성 코로나19 / 기후변화 / Starter Kit 세션별 전문가 발제 및 질의응답 |
| 2020.06.12 ~ 06.13 | Korea Virtual Hackathon 전문가 멘토와 함께 무박 2일 해커톤 진행 서울시장상, 한국IBM 사장상 표창 |

| 회의 | 날짜 | 주제 |
|---|---|---|
| 1차 | 2020.04.29 | 주제에 따른 각자 아이디어 구상 회의 |
| 2차 | 2020.05.03 | 아이디어 2개씩 선택 후 세부 기술 조사 |
| 3차 | 2020.05.07 | 아이디어 선택 회의 |
| 4차 | 2020.05.24 | 아이디어 재정비 회의 |
| 5차 | 2020.05.27 | 아이디어 구체화 후 세부 일정 정리 |
| 6차 | 2020.06.01 | IBM 클라우드 선정 및 공부 (Speech to Text) |
| 7차 | 2020.06.08 | 진행 상황 공유 및 공통 과제 회의 |
| 8차 | 2020.06.09 | 진행 상황 공유 및 공통 과제 회의 |
| 9차 | 2020.06.10 | 개인 공부 바탕으로 결과물 제작(미리, 호연, 세경) |
| 10차 | 2020.06.11 | 개인 공부 바탕으로 결과물 제작(정원, 현우) |
| 팀 1818 | 노션 회의록 | https://www.notion.so/ibmhackathonssafy03/7b32393d451f478995235f1015990835 |
| Person | 역할 | 세부사항 |
|---|---|---|
| 김호연 | 팀장, 개발 | 모든 파트 보조, 백엔드 개발 |
| 곽세경 | 디자이너, 개발 | 서비스 플랫폼 디자인, 백엔드 개발 |
| 박현우 | 개발 | 프론트, 백엔드 개발 |
| 최미리 | 기획, 개발 | 기획안 작성, 기능 테스트, 개발 보조 |
| 최정원 | 개발 | 프론트, 백엔드 개발 |
팀 1818의 프로젝트 목표
-
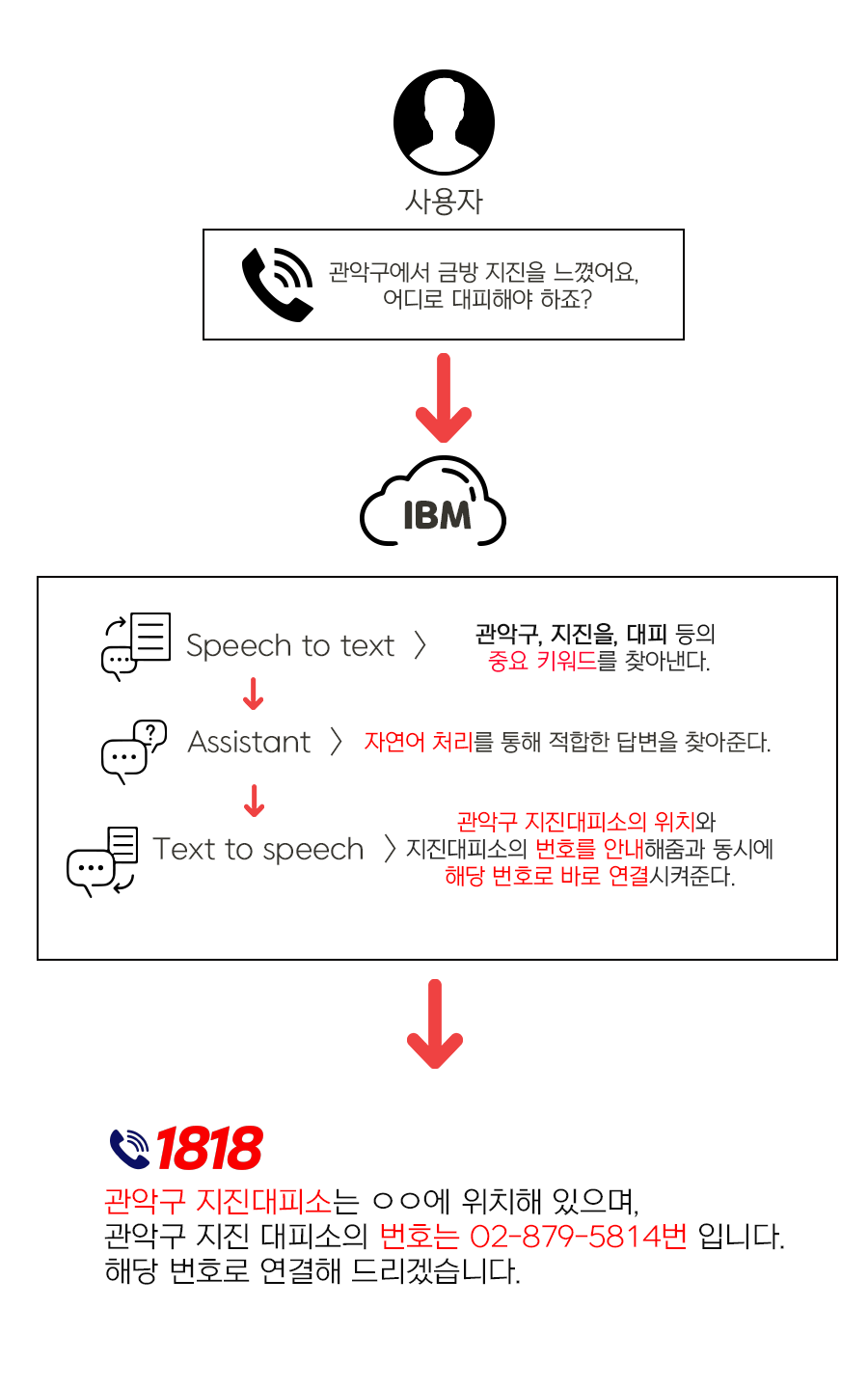
AI 기반 공공 전화 연결 서비스 "1818"
-
Watson의 Speech to text, Assistance, Text to speech 사용
-
1818 번으로 전화 연결시, 사용자가 필요로 하는 서비스를 분석하여 관련 연락처 및 정보를 제공하는 서비스
-
자연어 처리를 통해 1차로 즉각적인 정보를 제공해준다.
-
1차 필터링이 해결되지 않는 경우, 필요한 서비스에 맞는 공공기관 연락처로 연결해주는 2차 과정이 진행됨.
-
재난 상황에서 신고와 민원이 과부하 되는 것을 1차적으로 막고, 인터넷 사용이 불가한 상황에서도 사용 가능.
-
평소에도 간단한 정보 제공 역할을 하며 지속적으로 사용 가능하다.
-
이 서비스를 통해 얻은 데이터들로 앞으로의 재난을 예방하고 분석하는 서비스로 발전할 수 있음.
-
Watson의 STT 솔루션을 활용하여 사용자의 음성을 텍스트 처리하는 모듈 개발
- 예시 코드
from ibm_watson import TextToSpeechV1 from ibm_cloud_sdk_core.authenticators import IAMAuthenticator authenticator = IAMAuthenticator('{apikey}') text_to_speech = TextToSpeechV1( authenticator=authenticator ) text_to_speech.set_service_url('{url}') with open('hello_world.wav', 'wb') as audio_file: audio_file.write( text_to_speech.synthesize( 'Hello world', voice='en-US_AllisonV3Voice', accept='audio/wav' ).get_result().content)
- 수정 코드
import json from os.path import join, dirname from ibm_watson import SpeechToTextV1 from ibm_cloud_sdk_core.authenticators import IAMAuthenticator # authenticator 지정 def authenticate(k): authenticator = IAMAuthenticator(k) return authenticator def stt(a): speech_to_text = SpeechToTextV1(authenticator=a) return speech_to_text # 얘는 views.py에서 만들기 def set_url(stt, api_url): stt.set_service_url(api_url) return stt
-
STT의 결과를 통해 원하는 키워드 값을 추출하는 모듈 개발
- 예시 코드
import json from os.path import join, dirname from ibm_watson import SpeechToTextV1 from ibm_cloud_sdk_core.authenticators import IAMAuthenticator authenticator = IAMAuthenticator('{apikey}') speech_to_text = SpeechToTextV1( authenticator=authenticator ) speech_to_text.set_service_url('{url}') with open(join(dirname(__file__), './.', 'audio-file2.flac'), 'rb') as audio_file: speech_recognition_results = speech_to_text.recognize( audio=audio_file, content_type='audio/flac', word_alternatives_threshold=0.9, keywords=['colorado', 'tornado', 'tornadoes'], keywords_threshold=0.5 ).get_result() print(json.dumps(speech_recognition_results, indent=2))
- 수정 코드
# open 함수화 def start_stt(stt, filename): with open(join(dirname(__file__), '../media/timeline_audio', filename), 'rb') as audio_file: speech_recognition_results = stt.recognize( audio=audio_file, content_type='audio/wav', model='en-US_ShortForm_NarrowbandModel', word_alternatives_threshold=0.9, keywords=['\ub54c\ubb38\uc5d0', '\uc790\uafb8'], keywords_threshold=0.5 ).get_result() return speech_recognition_results def get_keyword(srr): keyword = dict(srr, indent=2)["results"][0]["alternatives"][0]["transcript"] return keyword
-
추출된 키워드 데이터를 Watson의 assistant 솔루션을 활용해 알맞은 데이터를 연결하는 모듈 개발
- 예시 코드
import json from ibm_watson import AssistantV2 from ibm_cloud_sdk_core.authenticators import IAMAuthenticator authenticator = IAMAuthenticator('{apikey}') assistant = AssistantV2( version='2020-04-01', authenticator = authenticator ) assistant.set_service_url('{url}') response = assistant.message_stateless( assistant_id='{assistant_id}', input={ 'message_type': 'text', 'text': 'Hello' } ).get_result() print(json.dumps(response, indent=2))
- 수정 코드
import json from ibm_watson import AssistantV2 from ibm_cloud_sdk_core.authenticators import IAMAuthenticator def authenticate(api_key): authenticator = IAMAuthenticator(api_key) return authenticator def set_assistant(authenticator): assistant = AssistantV2( version='2020-04-01', authenticator= authenticator ) return assistant def set_url(assistant, api_url): assistant.set_service_url(api_url) return assistant def get_response(assistant, a_id, text): response = assistant.message_stateless( assistant_id= a_id, input={ 'message_type': 'text', 'text': text } ).get_result() texts = response['output']['generic'][0]['text'] return texts
-
Watson의 TTS솔루션을 활용하여 연결된 데이터를 다시 음성으로 변환하는 모듈 개발
- 코드
from os.path import join, dirname from ibm_watson import TextToSpeechV1 from ibm_cloud_sdk_core.authenticators import IAMAuthenticator def authenticate(k): authenticator = IAMAuthenticator(k) return authenticator def tts(a): speech_to_text = TextToSpeechV1(authenticator=a) return speech_to_text def set_url(tts, api_url): tts.set_service_url(api_url) return tts def start_tts(tts, filename, text): with open(join(dirname(__file__), '../media/timeline_audio', filename), 'wb') as audio_file: audio_file.write( tts.synthesize( text, voice='en-US_MichaelV3Voice', accept='audio/wav' ).get_result().content)
-
사용자가 서비스를 이용할 수 있도록 Django를 활용하여 웹으로 구현