A Markhov Decision Process to demonstrate reinforcement learning.
This MDP assumes that the agent has recently graduated from their undergrad program, and the agent must now choose one of three choices:
- Get a full time job and join the workforce
- Go to grad school
- Start a part time/online grad school program, while working full time
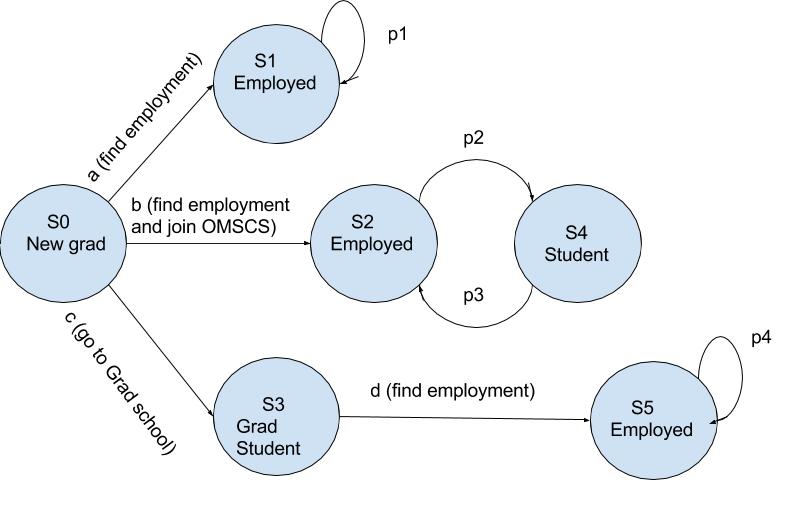
The system is stochastic, and each choice has its own reward.
The MDP leverages the BURLAP library (burlap.cs.brown.edu), and performs policy iteration, value iteration, and Q learning.