


You're tired of AI agents writing code that 'just works' but fits like a square peg in a round hole - not your conventions, not your architecture, not your repo. Even with well-curated instructions. You correct the agent, it doesn't remember. Next session, same mistakes.
This MCP gives agents just enough context so they match how your team codes, know why, and remember every correction.
Here's what codebase-context does:
Finds the right context - Search that doesn't just return code. Each result comes back with analyzed and quantified coding patterns and conventions, related team memories, file relationships, and quality indicators. It knows whether you're looking for a specific file, a concept, or how things wire together - and filters out the noise (test files, configs, old utilities) before the agent sees them. The agent gets curated context, not raw hits.
Knows your conventions - Detected from your code and git history, not only from rules you wrote. Seeks team consensus and direction by adoption percentages and trends (rising/declining), golden files. Tells the difference between code that's common and code that's current - what patterns the team is moving toward and what's being left behind.
Remembers across sessions - Decisions, failures, workarounds that look wrong but exist for a reason - the battle scars that aren't in the comments. Recorded once, surfaced automatically so the agent doesn't "clean up" something you spent a week getting right. Conventional git commits (refactor:, migrate:, fix:) auto-extract into memory with zero effort. Stale memories decay and get flagged instead of blindly trusted.
Checks before editing - Before editing something, you get a decision card showing whether there's enough evidence to proceed. If a symbol has four callers (files that import or reference it) and only two appear in your search results, the card shows that coverage gap. If coverage is low, whatWouldHelp lists the specific searches to run before you touch anything. When code, team memories, and patterns contradict each other, it tells you to look deeper instead of guessing.
One tool call returns all of it. Local-first - your code never leaves your machine by default. Opt into EMBEDDING_PROVIDER=openai for cloud speed, but then code is sent externally.
The index auto-refreshes as you edit - a file watcher triggers incremental reindex in the background when the MCP server is running. No stale context between tool calls.
Real CLI output against angular-spotify, the repo used for the launch screenshots.
Lead signal: pattern drift and golden files
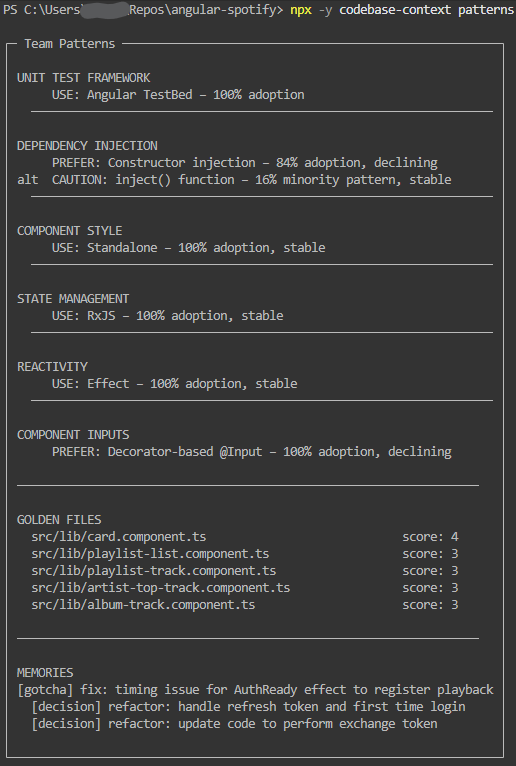
This is the part most tools miss: what the team is doing now, what it is moving away from, and which files are the best examples to follow.
Before editing: preflight and impact
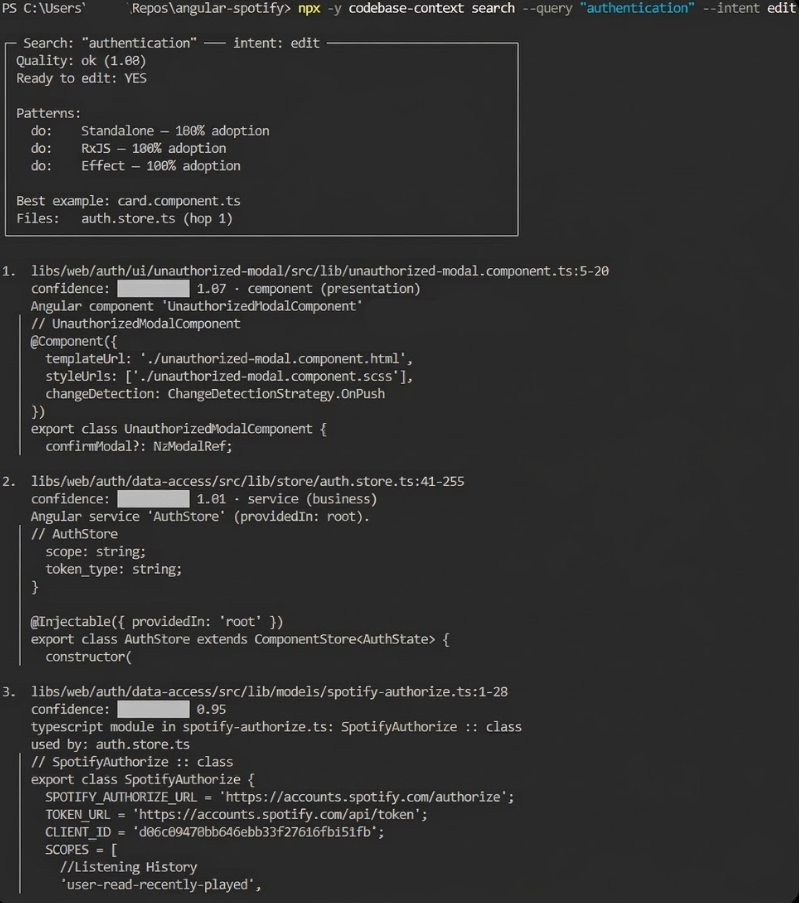
When the agent searches with edit intent, it gets a compact decision card: confidence, whether it's safe to proceed, which patterns apply, the best example, and which files are likely to be affected.
More CLI examples:
refs --symbol "ComponentStore"for concrete static referencesmetadatafor a quick codebase overview- Full gallery in
docs/cli.md
- Quick Start
- Multi-Project and Monorepos
- Test It Yourself
- Common First Commands
- What It Actually Does
- Evaluation Harness (
npm run eval) - How the Search Works
- Language Support
- Configuration
- Performance
- File Structure
- CLI Reference
- What to add to your CLAUDE.md / AGENTS.md
- Links
- License
Start with the default setup:
- Configure one
codebase-contextserver with no project path. - If a tool call later returns
selection_required, retry withproject. - If you only use one repo, you can also append that repo path up front.
| Situation | Recommended config |
|---|---|
| Default setup | Run npx -y codebase-context with no project path |
| Single repo setup | Append one project path or set CODEBASE_ROOT |
| Multi-project call is still ambiguous | Retry with project, or keep separate server entries if your client cannot preserve project context |
Add it to the configuration of your AI Agent of preference:
claude mcp add codebase-context -- npx -y codebase-contextAdd to claude_desktop_config.json:
{
"mcpServers": {
"codebase-context": {
"command": "npx",
"args": ["-y", "codebase-context"]
}
}
}Add .vscode/mcp.json to your project root:
{
"servers": {
"codebase-context": {
"command": "npx",
"args": ["-y", "codebase-context"] // Or append "${workspaceFolder}" for single-project use
}
}
}Add to .cursor/mcp.json in your project:
{
"mcpServers": {
"codebase-context": {
"command": "npx",
"args": ["-y", "codebase-context"]
}
}
}Open Settings > MCP and add:
{
"mcpServers": {
"codebase-context": {
"command": "npx",
"args": ["-y", "codebase-context"]
}
}
}Add opencode.json to your project root:
{
"$schema": "https://opencode.ai/config.json",
"mcp": {
"codebase-context": {
"type": "local",
"command": ["npx", "-y", "codebase-context"],
"enabled": true
}
}
}OpenCode also supports interactive setup via opencode mcp add.
codex mcp add codebase-context npx -y codebase-contextThat single config entry is the intended starting point.
If you only use one repo, append a project path:
codex mcp add codebase-context npx -y codebase-context "/path/to/your/project"Or set:
CODEBASE_ROOT=/path/to/your/projectThe MCP server can serve multiple projects in one session without requiring one MCP config entry per repo.
Three cases matter:
| Case | What happens |
|---|---|
| One project | Routing is automatic |
| Multiple projects and the client provides enough workspace context | The server can route across those projects in one MCP session |
| Multiple projects and the target is still ambiguous | The server does not guess. Use project explicitly |
Important rules:
projectis the explicit override when routing is ambiguous.projectaccepts a project root path, file path,file://URI, or a relative subproject path under a configured workspace such asapps/dashboard.- If a client reads
codebase://contextbefore any project is active, the server returns a workspace overview instead of guessing. - The server does not rely on
cwdwalk-up in MCP mode.
Typical explicit retry in a monorepo:
{
"name": "search_codebase",
"arguments": {
"query": "auth interceptor",
"project": "apps/dashboard"
}
}Or target a repo directly:
{
"name": "search_codebase",
"arguments": {
"query": "auth interceptor",
"project": "/repos/customer-portal"
}
}Or pass a file path and let the server resolve the nearest trusted project boundary:
{
"name": "search_codebase",
"arguments": {
"query": "auth interceptor",
"project": "/repos/monorepo/apps/dashboard/src/auth/guard.ts"
}
}If you see selection_required, the server could not tell which project you meant. The response looks like this:
{
"status": "selection_required",
"errorCode": "selection_required",
"message": "Multiple projects are available and no active project could be inferred. Retry with project.",
"nextAction": "retry_with_project",
"availableProjects": [
{ "label": "app-a", "project": "/repos/app-a", "indexStatus": "idle", "source": "root" },
{ "label": "app-b", "project": "/repos/app-b", "indexStatus": "ready", "source": "root" }
]
}Retry the call with project set to one of the listed paths.
codebase://context follows the active project in the session. In unresolved multi-project sessions it returns a workspace overview. Project-scoped resources are also available via the URIs listed in that overview.
The CLI stays intentionally simpler: it targets one repo per invocation via CODEBASE_ROOT or the current working directory. Multi-project discovery and routing are MCP-only features, not a second CLI session model.
Build the local branch first:
pnpm buildThen point your MCP client at the local build:
{
"mcpServers": {
"codebase-context": {
"command": "node",
"args": ["<path-to-local-build>/dist/index.js"]
}
}
}If the default setup is not enough for your client, use this instead:
{
"mcpServers": {
"codebase-context": {
"command": "node",
"args": ["<path-to-local-build>/dist/index.js", "/path/to/your/project"]
}
}
}Check these three flows:
-
Single project Ask for
search_codebaseormetadata. Expected: routing is automatic. -
Multiple projects with one server entry Open two repos or one monorepo workspace. Ask for
codebase://context. Expected: workspace overview first, then automatic routing once one project is active or unambiguous. -
Ambiguous project selection Start without a bootstrap path. Ask for
search_codebase. Expected:selection_required. Retry withproject, for exampleapps/dashboardor/repos/customer-portal.
For monorepos, verify all three selector forms:
- relative subproject path:
apps/dashboard - repo path:
/repos/customer-portal - file path:
/repos/monorepo/apps/dashboard/src/auth/guard.ts
Three commands to get what usually takes a new developer weeks to piece together:
# What tech stack, architecture, and file count?
npx -y codebase-context metadata
# What does the team actually code like right now?
npx -y codebase-context patterns
# What team decisions were made (and why)?
npx -y codebase-context memory listThis is also what your AI agent consumes automatically via MCP tools; the CLI is the human-readable version.
$ npx -y codebase-context patterns
┌─ Team Patterns ──────────────────────────────────────────────────────┐
│ │
│ UNIT TEST FRAMEWORK │
│ USE: Vitest – 96% adoption │
│ alt CAUTION: Jest – 4% minority pattern │
│ │
│ STATE MANAGEMENT │
│ PREFER: RxJS – 63% adoption │
│ alt Redux-style store – 25% │
│ │
└──────────────────────────────────────────────────────────────────────┘
$ npx -y codebase-context search --query "file watcher" --intent edit --limit 1
┌─ Search: "file watcher" ─── intent: edit ────────────────────────────┐
│ Quality: ok (1.00) │
│ Ready to edit: YES │
│ │
│ Best example: index.ts │
└──────────────────────────────────────────────────────────────────────┘
$ npx -y codebase-context metadata
┌─ codebase-context [monorepo] ────────────────────────────────────────┐
│ │
│ Framework: Angular unknown Architecture: mixed │
│ 130 files · 24,211 lines · 1077 components │
│ │
│ Dependencies: @huggingface/transformers · @lancedb/lancedb · │
│ @modelcontextprotocol/sdk · @typescript-eslint/typescript-estree · │
│ chokidar · fuse.js (+14 more) │
│ │
└──────────────────────────────────────────────────────────────────────┘
$ npx -y codebase-context refs --symbol "startFileWatcher"
┌─ startFileWatcher ─── 11 references ─── static analysis ─────────────┐
│ │
│ startFileWatcher │
│ │ │
│ ├─ file-watcher.test.ts:5 │
│ │ import { startFileWatcher } from '../src/core/file-watcher.... │
│ │
└──────────────────────────────────────────────────────────────────────┘
$ npx -y codebase-context cycles
┌─ Circular Dependencies ──────────────────────────────────────────────┐
│ │
│ No cycles found · 98 files · 260 edges · 2.7 avg deps │
│ │
└──────────────────────────────────────────────────────────────────────┘
See docs/cli.md for the full CLI gallery.
Other tools help AI find code. This one helps AI make the right decisions - by knowing what your team does, tracking where codebases are heading, and warning before mistakes happen.
| Without codebase-context | With codebase-context |
|---|---|
| Generates code using whatever matches or "sounds" right | Generates code following your team conventions |
| Copies any example that fits | Follows your best implementations (golden files) |
| Repeats mistakes you already corrected | Surfaces failure memories right before trying again |
| You re-explain the same things every session | Remembers conventions and decisions automatically |
| Edits confidently even when context is weak | Flags high-risk changes when evidence is thin |
| Sees what the current code does and assumes | Sees how your code has evolved and why |
This is where it all comes together. One call returns:
- Code results with
file(path + line range),summary,score - Type per result: compact
componentType:layer(e.g.,service:data) — helps agents orient - Pattern signals per result:
trend(Rising/Declining — Stable is omitted) andpatternWarningwhen using legacy code - Relationships per result:
importedByCountandhasTests(condensed) + hints (capped ranked callers, consumers, tests) — so you see suggested next reads and know what you haven't looked at yet - Related memories: up to 3 team decisions, gotchas, and failures matched to the query
- Search quality:
okorlow_confidencewith confidence score andhintwhen low - Preflight:
ready(boolean) with decision card whenintent="edit"|"refactor"|"migrate". ShowsnextAction(if not ready),warnings,patterns(do/avoid),bestExample,impact(import-graph coverage — how many files that import or reference the result are in your search), andwhatWouldHelp(next steps). If search quality is low,readyis alwaysfalse.
Snippets are optional (includeSnippets: true). When enabled, snippets that have symbol metadata (e.g. from the Generic analyzer's AST chunking or Angular component chunks) start with a scope header so you know where the code lives (e.g. // AuthService.getToken() or // SpotifyApiService). Example:
// AuthService.getToken()
getToken(): string {
return this.token;
}Default output is lean — if the agent wants code, it calls read_file.
For scripting and automation, every CLI command accepts --json for machine output (stdout = JSON; logs/errors go to stderr).
See docs/capabilities.md for the field reference.
Lean enough to fit on one screen. If search quality is low, preflight blocks edits instead of faking confidence.
Detects what your team actually does by analyzing the codebase:
- Adoption percentages for dependency injection, state management, testing, libraries
- Patterns/conventions trend direction (Rising / Stable / Declining) based on git recency
- Golden files - your best implementations ranked by modern pattern density
- Conflicts - when the team hasn't converged (both approaches above 20% adoption)
Record a decision once. It surfaces automatically in search results and preflight cards from then on. Your git commits also become memories - conventional commits like refactor:, migrate:, fix:, revert: from the last 90 days are auto-extracted during indexing.
- Types: conventions (style rules), decisions (architecture choices), gotchas (things that break), failures (we tried X, it broke because Y)
- Confidence decay: decisions age over 180 days, gotchas and failures over 90 days. Stale memories get flagged instead of blindly trusted.
- Zero-config git extraction: runs automatically during
refresh_index. No setup, no manual work.
| Tool | What it does |
|---|---|
search_codebase |
Hybrid search + decision card. Pass intent="edit" to get ready, nextAction, patterns, import-graph coverage, and whatWouldHelp. |
get_team_patterns |
Pattern frequencies, golden files, conflict detection |
get_symbol_references |
Find concrete references to a symbol (usageCount + top snippets). confidence: "syntactic" = static/source-based only; no runtime or dynamic dispatch. |
remember |
Record a convention, decision, gotcha, or failure |
get_memory |
Query team memory with confidence decay scoring |
get_codebase_metadata |
Project structure, frameworks, dependencies |
get_style_guide |
Style guide rules for the current project |
detect_circular_dependencies |
Import cycles between files |
refresh_index |
Re-index (full or incremental) + extract git memories |
get_indexing_status |
Progress and stats for the current index |
Reproducible evaluation with frozen fixtures so ranking/chunking changes are measured honestly and regressions get caught. For contributors and CI: run before releases or after changing search/ranking/chunking to guard against regressions.
- Two codebases:
npm run eval -- <codebaseA> <codebaseB> - Defaults: fixture A =
tests/fixtures/eval-angular-spotify.json, fixture B =tests/fixtures/eval-controlled.json - Offline smoke (no network):
npm run eval -- tests/fixtures/codebases/eval-controlled tests/fixtures/codebases/eval-controlled \
--fixture-a=tests/fixtures/eval-controlled.json \
--fixture-b=tests/fixtures/eval-controlled.json \
--skip-reindex --no-rerank- Flags:
--help,--fixture-a,--fixture-b,--skip-reindex,--no-rerank,--no-redact - To save a report for later comparison, redirect stdout (e.g.
pnpm run eval -- <path-to-angular-spotify> --skip-reindex > internal-docs/tests/eval-runs/angular-spotify-YYYY-MM-DD.txt).
The retrieval pipeline is designed around one goal: give the agent the right context, not just any file that matches.
- Definition-first ranking - for exact-name lookups (e.g. a symbol name), the file that defines the symbol ranks above files that only use it.
- Intent classification - knows whether "AuthService" is a name lookup or "how does auth work" is conceptual. Adjusts keyword/semantic weights accordingly.
- Hybrid fusion (RRF) - combines keyword and semantic search using Reciprocal Rank Fusion instead of brittle score averaging.
- Query expansion - conceptual queries automatically expand with domain-relevant terms (auth → login, token, session, guard).
- Contamination control - test files are filtered/demoted for non-test queries.
- Import centrality - files that are imported more often rank higher.
- Cross-encoder reranking - a stage-2 reranker triggers only when top scores are ambiguous. CPU-only, bounded to top-K.
- Incremental indexing - only re-indexes files that changed since last run (SHA-256 manifest diffing).
- Version gating - index artifacts are versioned; mismatches trigger automatic rebuild so mixed-version data is never served.
- Auto-heal - if the index corrupts, search triggers a full re-index automatically.
Index reliability: Rebuilds write to a staging directory and swap atomically only on success, so a failed rebuild never corrupts the active index. Version mismatches or corruption trigger an automatic full re-index (no user action required).
10 languages have full symbol extraction (Tree-sitter): TypeScript, JavaScript, Python, Java, Kotlin, C, C++, C#, Go, Rust. 30+ languages have indexing and retrieval coverage (keyword + semantic), including PHP, Ruby, Swift, Scala, Shell, and config/markup (JSON/YAML/TOML/XML, etc.).
Enrichment is framework-specific: right now only Angular has a dedicated analyzer for rich conventions/context (signals, standalone components, control flow, DI patterns).
For non-Angular projects, the Generic analyzer uses AST-aligned chunking when a Tree-sitter grammar is available: symbol-bounded chunks with scope-aware prefixes (e.g. // ClassName.methodName) so snippets show where code lives. Without a grammar it falls back to safe line-based chunking.
Structured filters available: framework, language, componentType, layer (presentation, business, data, state, core, shared).
| Variable | Default | Description |
|---|---|---|
EMBEDDING_PROVIDER |
transformers |
openai (fast, cloud) or transformers (local, private) |
OPENAI_API_KEY |
- | Required only if using openai provider |
CODEBASE_ROOT |
- | Optional bootstrap root for CLI and single-project MCP clients without roots |
CODEBASE_CONTEXT_DEBUG |
- | Set to 1 for verbose logging |
EMBEDDING_MODEL |
Xenova/bge-small-en-v1.5 |
Local embedding model override (e.g. onnx-community/granite-embedding-small-english-r2-ONNX for Granite) |
- First indexing: 2-5 minutes for ~30k files (embedding computation).
- Subsequent queries: milliseconds from cache.
- Incremental updates:
refresh_indexwithincrementalOnly: trueprocesses only changed files (SHA-256 manifest diffing).
.codebase-context/
memory.json # Team knowledge (should be persisted in git)
index-meta.json # Index metadata and version (generated)
intelligence.json # Pattern analysis (generated)
relationships.json # File/symbol relationships (generated)
index.json # Keyword index (generated)
index/ # Vector database (generated)
Recommended .gitignore:
# Codebase Context - ignore generated files, keep memory
.codebase-context/*
!.codebase-context/memory.jsonRepo-scoped analysis commands are available via the CLI — no AI agent required. MCP multi-project routing uses the shared project selector when needed; the CLI stays one-root-per-invocation.
For formatted examples and “money shots”, see docs/cli.md.
Set CODEBASE_ROOT to your project root, or run from the project directory.
# Search the indexed codebase
npx -y codebase-context search --query "authentication middleware"
npx -y codebase-context search --query "auth" --intent edit --limit 5
# Project structure, frameworks, and dependencies
npx -y codebase-context metadata
# Index state and progress
npx -y codebase-context status
# Re-index the codebase
npx -y codebase-context reindex
npx -y codebase-context reindex --incremental --reason "added new service"
# Style guide rules
npx -y codebase-context style-guide
npx -y codebase-context style-guide --query "naming" --category patterns
# Team patterns (DI, state, testing, etc.)
npx -y codebase-context patterns
npx -y codebase-context patterns --category testing
# Symbol references
npx -y codebase-context refs --symbol "UserService"
npx -y codebase-context refs --symbol "handleLogin" --limit 20
# Circular dependency detection
npx -y codebase-context cycles
npx -y codebase-context cycles --scope src/features
# Memory management
npx -y codebase-context memory list
npx -y codebase-context memory list --category conventions --type convention
npx -y codebase-context memory list --query "auth" --json
npx -y codebase-context memory add --type convention --category tooling --memory "Use pnpm, not npm" --reason "Workspace support and speed"
npx -y codebase-context memory remove <id>All commands accept --json for raw JSON output suitable for piping and scripting.
Paste this into .cursorrules, CLAUDE.md, AGENTS.md, or wherever your AI reads project instructions:
## Codebase Context (MCP)
**Start of every task:** Call `get_memory` to load team conventions before writing any code.
**Before editing existing code:** Call `search_codebase` with `intent: "edit"`. If the preflight card says `ready: false`, read the listed files before touching anything.
**Before writing new code:** Call `get_team_patterns` to check how the team handles DI, state, testing, and library wrappers — don't introduce a new pattern if one already exists.
**When asked to "remember" or "record" something:** Call `remember` immediately, before doing anything else.
**When adding imports that cross module boundaries:** Call `detect_circular_dependencies` with the relevant scope after adding the import.These are the behaviors that make the most difference day-to-day. Copy, trim what doesn't apply to your stack, and add it once.
- Motivation - Research and design rationale
- Changelog - Version history
- Contributing - How to add analyzers
MIT