ICP4
Q1 Implement Naïve Bayes method using scikit-learn Use iris dataset available in https://umkc.box.com/s/pm3cebmhxpnczi6h87k2lwwiwdvtxyk8Use cross validation to create training and testing part Evaluate the model on testing part
Solution 1: Naive Bayes is one of the simplest supervised learning algorithm. It is a statistical classification technique. It is fast,accurate and reliable algorithm.
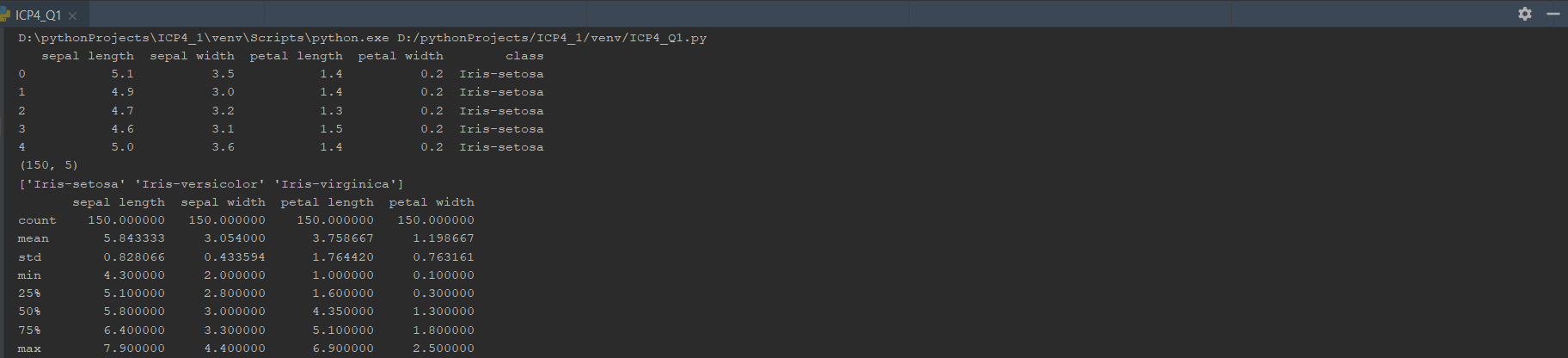
OUTPUT:-
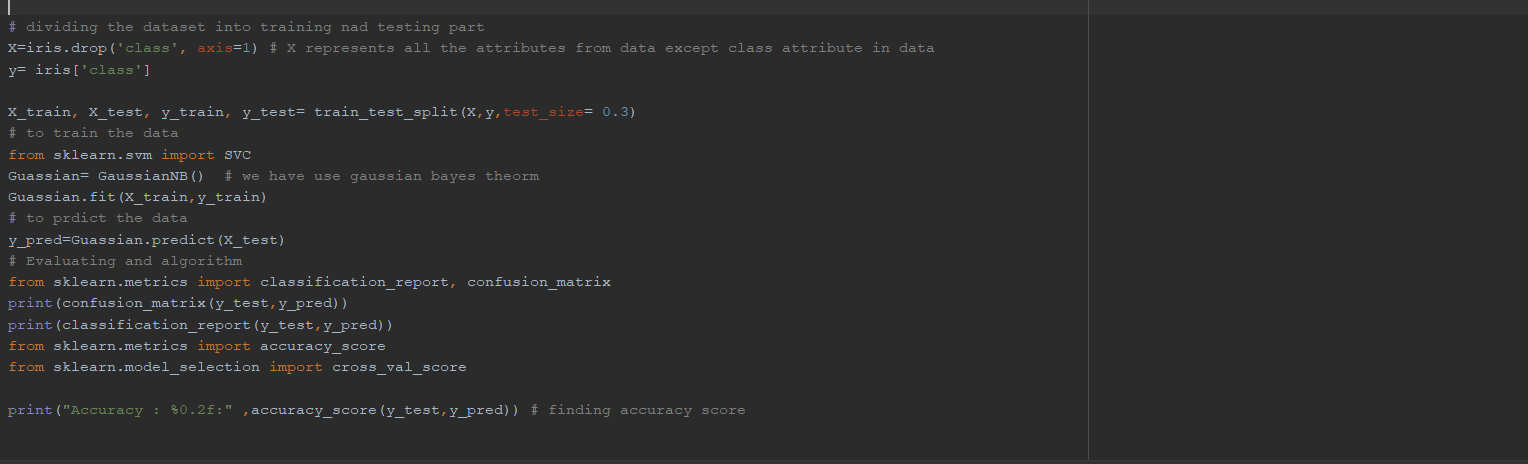
OUTPUT:

Q2. Implement linear SVMmethodusing scikit libraryUse the samedataset above.
Solution 2: We use Linear SVM that is support Vector machine.
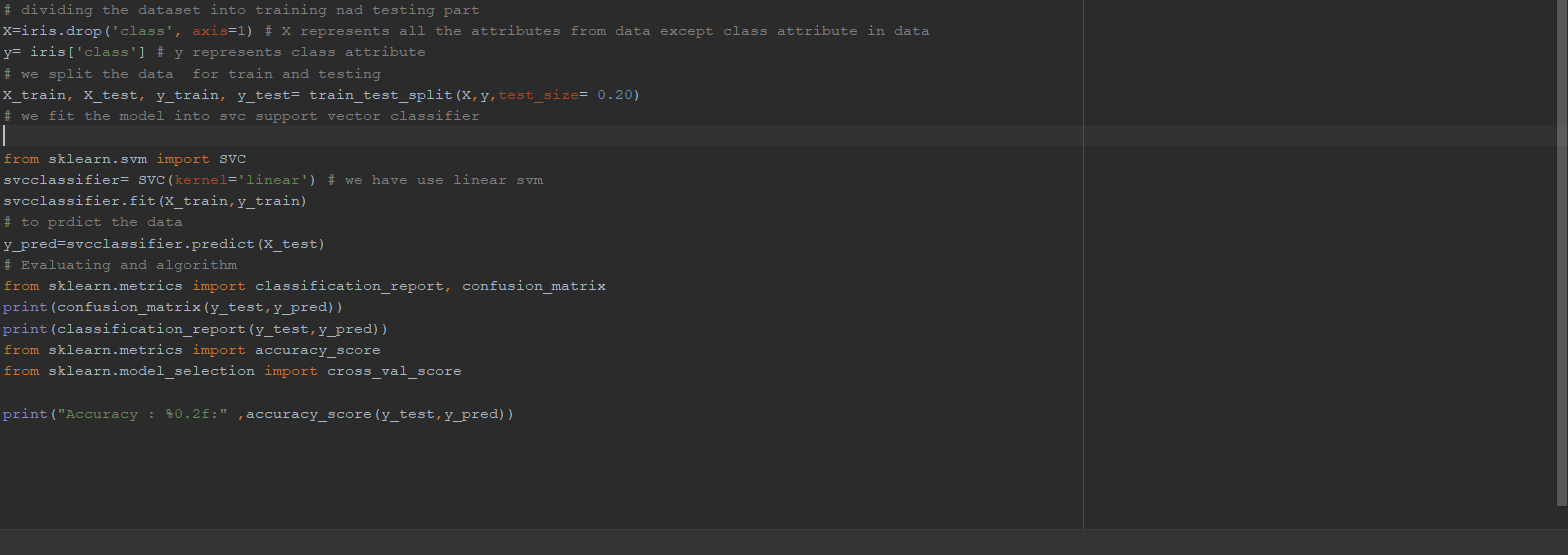
Output

Q3. Compare the results and report accuracy, precision, F-measure and Recall Solution 3 is already implemented in solution 1 and solution 2 code.
Naive Bayes algorithm: The model is very accurate in calculating precision score of iris setosa and versicolor that is Positive/All=1.0. For virginica it is low that is 0.9/14. But accuracy score is 0.97.
SVM: The model is very accurate in claculating the precision score of setosa and virginica that is Positive/ALL=1.0. For versicolor, it is very low. Accuracy score also differs with test size that is 0.96