前言
第二章 - 在设计云应用时,架构方面的考虑
由于架设在云上的应用很多的时候是提供Paas或者SaaS的服务,那么有可能是服务于多种不同的用户的,这些用户对于平台的需求不尽相同,归结起来,可以有以下方面的考虑:
- 多层 (Multi-tier)架构
- 多租户 (multi-tenancy)下的设计,其中包括数据安全以及可扩展性的设计。
- 容量扩展性设计 (Designing for scale)
- 可自动化基础架构
- 为部分功能失效而做的设计
- 并行处理
- 性能设计
- 对于最终一致性(eventual consistency)的设计
- 估算云计算的成本
多层架构
基本上对于一种web应用来说一种简单的多层架构包括UI层 (Web Server - 对应于MVC中的View),应用层(application - 用于处理具体的也许需求,可以理解成逻辑层 - 对应于MVC中的Controller)以及对数据库描述的数据层(对应于MVC中的Model)。
基于云的多层结构可以做到这几层在不同的物理位置或者是不在一个数据中心的机房内,那么三者之间可以通过TCP或者是TLS/SSL进行通信,UI层/应用层可以分别放置到不同的集群内,这样可以通过负载均衡服务器来达到均匀调度的目的。
如下图:
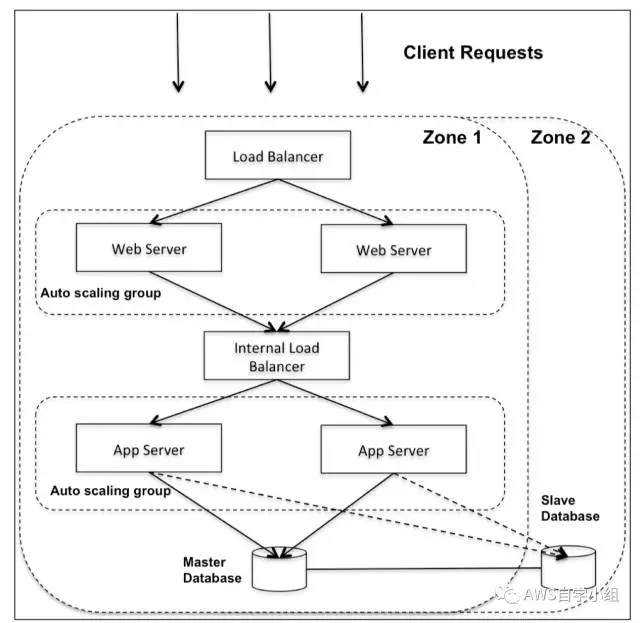
考虑到冗余性,可以将该三层在两个不同的物理位置启动一份备份,这样通过DNS来保证当一个区域的服务down掉后,能通过另外的区域的server保证服务的正常运行,对于数据层来说,通过冗余备份机制保证主从服务器的一致性。
多租户设计
对于提供了PaaS或者SaaS的云服务的提供商来说,仍然需要考虑多租户问题。
在应用层上要运行在不同的进程中保证彼此的数据是隔离的,在数据层上要考虑集中不同的数据库隔离方案,例如,隔离数据库、共享数据库隔离数据架构、共享数据库共享数据架构等方案。除此之外还要考虑到由于数据库升级、备份、恢复带来的数据操作问题,以及相关问题引入的复杂性。
数据安全性
数据安全性首先是存储的安全性,从租户的角度来说,租户在数据库中的数据不能够让任意的租户访问,因此PaaS、SaaS需要能够通过租户的标识创建的访问控制列表来访问租户对应的数据库或者是共享表中的对应的行。
另外来说就是访问的安全性,这里指的是对于一个组织来说,他存储的数据库的内容不一定对所有该组织的所有人有着同样的访问权限,例如只有数据库管理员能够增删表项,而其他用户可能只有度的权限。因此需要对该组织内的用户进行安全组设计。
除此之外,还需要对于敏感信息需要进行加密处理,但是对于所有数据都加密又会导致性能的继续下降,这里需要考虑加密数据量级问题。
数据的扩展性
在使用非隔离数据库的方案时,对于PaaS架构的云上的提供商来说,扩展数据库是个常见功能,由于PaaS功能是可以存在多租户的方式,那么就涉及到表扩展性的问题,如果是直接对表进行插入列的方式会带来一系列的问题,例如一个租户的需求导致其他租户的访问受限或者无法提供服务。另外插入的列的名称可能不一致导致表空间的浪费等。
现在一种解决办法是在表构建的时候提前预留一些列出来来应付对于表扩展的需求,这些预留出来的列对于不同租户有着不同的含义,所以需要另外一张表来标识这些列对于某个租户是什么含义。例如 field1对于租户1和2来说代表着不同的含义,对于租户1来说field1意味着地址信息、而对于租户2来说field1是表示为街道信息:

另外一个对于应对表扩展的方式是将横向扩展变为列扩展,在上述增加了一个描述表之外,需要另外一个表来存储该表格的值。例如,对于租户1的来说customer_id为23的客户对应的扩展域record_id为11,那么在metadata表中对应该record_id为11的表项有3行数据,分别对应metadata为111 112 113的三个数据,这三个值通过另外的meta表格来解释该三项值得含义,分别为地址,生日以及家庭电话号码:
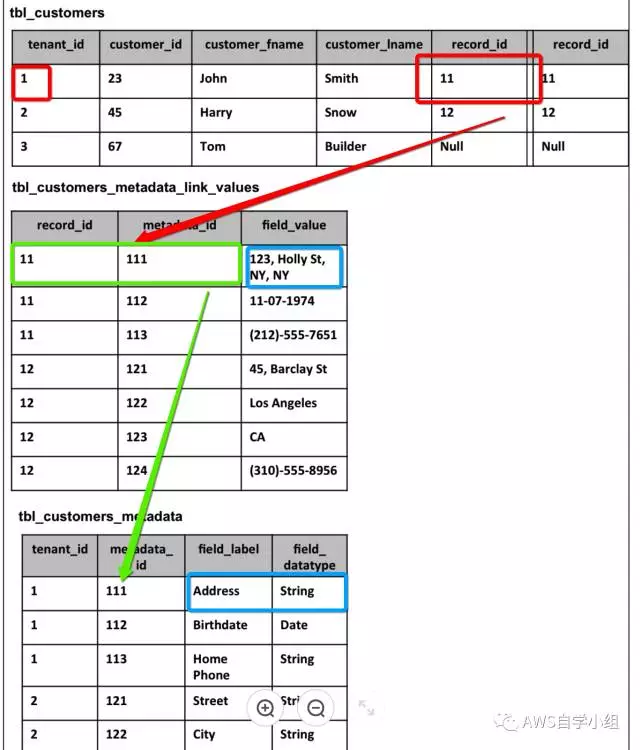
以上两种是数据分离的方式处理的,也就是对于租户的客户元信息内容(具体的地址,生日等)都分别存储在可以索引的唯一项上,而另外还有一种聚合存储的方式,用xml或者是其他格式信息,将该信息聚合存储在扩展域内。该方法比较简单,但是非常不利于数据的检索处理。这里不做过多分析。
超脱出关系型数据库的范畴,对于以上需求,使用NoSQL也是一种有效的手段。
适用于多租户的应用程序
当数据库中使用了租户id (tenant id)后,对于Web应用程序或者后端的应用程序来说都要适应多租户的情况,此种情况比较适用于SaaS的软件提供商,例如你提供了数据报表的处理方式,那么需要对不同的客户(公司)提供不同的报表处理的逻辑的需要,web前端也要考虑不同公司或个人如何进行身份认证等。
容量设计
对于云上的服务,容量设计至关重要。对于传统的数据中心的业务,对于容量来说,考虑的因素意味着数据中心的节点达到了CPU、内存、磁盘和网络带宽的某个阈值所能够支撑的业务情况,此种情况下,一般来说,我们需要购买更多的设备来满足业务增长的需求。
一般来说,有两种扩容的方式 - scale up (纵向扩展 - 购买更加强大的设备)或者是scale out (水平扩展 - 增加同等级别的机器的数量)。对于云端的业务来说,两种扩展方式都是可行的,进一步来讲,scale out的方式能够通过自动化地来完成,并且具有提高资源利用率和使得成本更加可控的优势。
为了能够使得跑在云端环境上的程序能够更好的支持scale out,一般来说这些应用程序需要设计成无状态的方式, 在此种方式下的应用,能够随意的增加机器的数量和删除机器的数量而不会造成对功能的影响。应用程序在一般运行期都会携带一些状态,如果这些状态非常重要,那么这些状态需要存储在可持久化的数据库或者cache中。
数据库的scale out通常来说是通过数据库分片 (sharding)来完成的,sharding指的是将数据库访问比较相关性强的数据存储在一起,进一步将数据库分割存储。
对于架构上,保持松耦合是被广泛任何的设计方式和最佳实践。为了构建更加高容量的应用,松耦合的系统能够使得部分系统可以得意关闭。最常用的实现松耦合的方式是在多个处理组件之间使用队列来进行消息交互。大部分的云服务提供商都提供了队列服务(queuing service),这些队列服务能够满足高并发以及高峰值的要求。
在云端的系统中队列服务使用分布式队列的方式 (distributed queue),分布式队列将队列消息复制多份在不同的队列里。因此在应用程序的设计方面要考虑如下几点:
- 消息顺序是不被确保的。乱序移动会存在的。
- 被处理的消息可能不会被删除掉 (因为分布式队列的关系),因为消息的处理是可重入的。
自动化架构
由于容量是可以伸缩的,那么要有可以自动化的架构来处理对容量伸缩的要求。
失效设计
对于基于用的应用来说,考虑到所有可以考虑的失效的情况 (例如,云数据中心失效,断电等等),应用程序应当优雅的处理这些情况以达到对客户的最小影响。
同时对于失效的情况,可要尽量少需要人来介入尽量,而是使用云平台已经提供的机制来处理这些情况。例如CloudFoundation服务中有一些列的基于cloud-init脚本,可以在自己的CouldFoundation模板中使用这些脚本来实现自动化的安装,配置以及升级的功能。
几下几点能够使得能够在云端处理失效情况更加高效:
不要本地保存应用程序状态,因为你的ec2 instance可能会被杀掉。
日志存储的中心化
日志中要有足够的上下文信息来提高问题的定位效率。
避免单点失败的情况。
并行处理设计
一般来说,在云端的业务能够通过多线程以及多节点的处理方式来达到并行处理的目的,在云端,由于可以auto-scaling,那么多节点的方式能够自动的方式得以进行。进一步来讲,可以例如类似于Hadoop的架构来处理和构建分布式应用程序。
性能设计(延迟)
在云端的应用来说,延迟成为了一个头疼的问题。
为了降低延迟,应用程序要cache经常访问的数据,减少对使用网络的情况,确保你的软件组件之间距离尽可能的近一些。并且要使用对于静态文件(css,js,img),使用CDN
最终一致性设计
由于在云端系统中,数据库一般都是分布式的,那么在多个数据库的操作上会有些许的延迟,那么导致数据库在某个事务确保原子性的前提下没有在一定时间内达到原子性的要求,但是在有限的时间内 (大概几秒钟内),数据库的操作完成后,能够将事务保证为一致,此为最终一致性。在云端的数据库中,最终一致性是缺省行为。
前言
第二章 - 在设计云应用时,架构方面的考虑
由于架设在云上的应用很多的时候是提供Paas或者SaaS的服务,那么有可能是服务于多种不同的用户的,这些用户对于平台的需求不尽相同,归结起来,可以有以下方面的考虑:
多层架构
基本上对于一种web应用来说一种简单的多层架构包括UI层 (Web Server - 对应于MVC中的View),应用层(application - 用于处理具体的也许需求,可以理解成逻辑层 - 对应于MVC中的Controller)以及对数据库描述的数据层(对应于MVC中的Model)。

基于云的多层结构可以做到这几层在不同的物理位置或者是不在一个数据中心的机房内,那么三者之间可以通过TCP或者是TLS/SSL进行通信,UI层/应用层可以分别放置到不同的集群内,这样可以通过负载均衡服务器来达到均匀调度的目的。
如下图:
考虑到冗余性,可以将该三层在两个不同的物理位置启动一份备份,这样通过DNS来保证当一个区域的服务down掉后,能通过另外的区域的server保证服务的正常运行,对于数据层来说,通过冗余备份机制保证主从服务器的一致性。
多租户设计
对于提供了PaaS或者SaaS的云服务的提供商来说,仍然需要考虑多租户问题。
在应用层上要运行在不同的进程中保证彼此的数据是隔离的,在数据层上要考虑集中不同的数据库隔离方案,例如,隔离数据库、共享数据库隔离数据架构、共享数据库共享数据架构等方案。除此之外还要考虑到由于数据库升级、备份、恢复带来的数据操作问题,以及相关问题引入的复杂性。
数据安全性
数据安全性首先是存储的安全性,从租户的角度来说,租户在数据库中的数据不能够让任意的租户访问,因此PaaS、SaaS需要能够通过租户的标识创建的访问控制列表来访问租户对应的数据库或者是共享表中的对应的行。
另外来说就是访问的安全性,这里指的是对于一个组织来说,他存储的数据库的内容不一定对所有该组织的所有人有着同样的访问权限,例如只有数据库管理员能够增删表项,而其他用户可能只有度的权限。因此需要对该组织内的用户进行安全组设计。
除此之外,还需要对于敏感信息需要进行加密处理,但是对于所有数据都加密又会导致性能的继续下降,这里需要考虑加密数据量级问题。
数据的扩展性
在使用非隔离数据库的方案时,对于PaaS架构的云上的提供商来说,扩展数据库是个常见功能,由于PaaS功能是可以存在多租户的方式,那么就涉及到表扩展性的问题,如果是直接对表进行插入列的方式会带来一系列的问题,例如一个租户的需求导致其他租户的访问受限或者无法提供服务。另外插入的列的名称可能不一致导致表空间的浪费等。


现在一种解决办法是在表构建的时候提前预留一些列出来来应付对于表扩展的需求,这些预留出来的列对于不同租户有着不同的含义,所以需要另外一张表来标识这些列对于某个租户是什么含义。例如 field1对于租户1和2来说代表着不同的含义,对于租户1来说field1意味着地址信息、而对于租户2来说field1是表示为街道信息:
另外一个对于应对表扩展的方式是将横向扩展变为列扩展,在上述增加了一个描述表之外,需要另外一个表来存储该表格的值。例如,对于租户1的来说customer_id为23的客户对应的扩展域record_id为11,那么在metadata表中对应该record_id为11的表项有3行数据,分别对应metadata为111 112 113的三个数据,这三个值通过另外的meta表格来解释该三项值得含义,分别为地址,生日以及家庭电话号码:
以上两种是数据分离的方式处理的,也就是对于租户的客户元信息内容(具体的地址,生日等)都分别存储在可以索引的唯一项上,而另外还有一种聚合存储的方式,用xml或者是其他格式信息,将该信息聚合存储在扩展域内。该方法比较简单,但是非常不利于数据的检索处理。这里不做过多分析。
超脱出关系型数据库的范畴,对于以上需求,使用NoSQL也是一种有效的手段。
适用于多租户的应用程序
当数据库中使用了租户id (tenant id)后,对于Web应用程序或者后端的应用程序来说都要适应多租户的情况,此种情况比较适用于SaaS的软件提供商,例如你提供了数据报表的处理方式,那么需要对不同的客户(公司)提供不同的报表处理的逻辑的需要,web前端也要考虑不同公司或个人如何进行身份认证等。
容量设计
对于云上的服务,容量设计至关重要。对于传统的数据中心的业务,对于容量来说,考虑的因素意味着数据中心的节点达到了CPU、内存、磁盘和网络带宽的某个阈值所能够支撑的业务情况,此种情况下,一般来说,我们需要购买更多的设备来满足业务增长的需求。
一般来说,有两种扩容的方式 - scale up (纵向扩展 - 购买更加强大的设备)或者是scale out (水平扩展 - 增加同等级别的机器的数量)。对于云端的业务来说,两种扩展方式都是可行的,进一步来讲,scale out的方式能够通过自动化地来完成,并且具有提高资源利用率和使得成本更加可控的优势。
为了能够使得跑在云端环境上的程序能够更好的支持scale out,一般来说这些应用程序需要设计成无状态的方式, 在此种方式下的应用,能够随意的增加机器的数量和删除机器的数量而不会造成对功能的影响。应用程序在一般运行期都会携带一些状态,如果这些状态非常重要,那么这些状态需要存储在可持久化的数据库或者cache中。
数据库的scale out通常来说是通过数据库分片 (sharding)来完成的,sharding指的是将数据库访问比较相关性强的数据存储在一起,进一步将数据库分割存储。
对于架构上,保持松耦合是被广泛任何的设计方式和最佳实践。为了构建更加高容量的应用,松耦合的系统能够使得部分系统可以得意关闭。最常用的实现松耦合的方式是在多个处理组件之间使用队列来进行消息交互。大部分的云服务提供商都提供了队列服务(queuing service),这些队列服务能够满足高并发以及高峰值的要求。
在云端的系统中队列服务使用分布式队列的方式 (distributed queue),分布式队列将队列消息复制多份在不同的队列里。因此在应用程序的设计方面要考虑如下几点:
自动化架构
由于容量是可以伸缩的,那么要有可以自动化的架构来处理对容量伸缩的要求。
失效设计
对于基于用的应用来说,考虑到所有可以考虑的失效的情况 (例如,云数据中心失效,断电等等),应用程序应当优雅的处理这些情况以达到对客户的最小影响。
同时对于失效的情况,可要尽量少需要人来介入尽量,而是使用云平台已经提供的机制来处理这些情况。例如CloudFoundation服务中有一些列的基于cloud-init脚本,可以在自己的CouldFoundation模板中使用这些脚本来实现自动化的安装,配置以及升级的功能。
几下几点能够使得能够在云端处理失效情况更加高效:
不要本地保存应用程序状态,因为你的ec2 instance可能会被杀掉。
日志存储的中心化
日志中要有足够的上下文信息来提高问题的定位效率。
避免单点失败的情况。
并行处理设计
一般来说,在云端的业务能够通过多线程以及多节点的处理方式来达到并行处理的目的,在云端,由于可以auto-scaling,那么多节点的方式能够自动的方式得以进行。进一步来讲,可以例如类似于Hadoop的架构来处理和构建分布式应用程序。
性能设计(延迟)
在云端的应用来说,延迟成为了一个头疼的问题。
为了降低延迟,应用程序要cache经常访问的数据,减少对使用网络的情况,确保你的软件组件之间距离尽可能的近一些。并且要使用对于静态文件(css,js,img),使用CDN
最终一致性设计
由于在云端系统中,数据库一般都是分布式的,那么在多个数据库的操作上会有些许的延迟,那么导致数据库在某个事务确保原子性的前提下没有在一定时间内达到原子性的要求,但是在有限的时间内 (大概几秒钟内),数据库的操作完成后,能够将事务保证为一致,此为最终一致性。在云端的数据库中,最终一致性是缺省行为。