diff --git a/blog/2026-01-16-training-inference-mismatch.md b/blog/2026-01-16-training-inference-mismatch.md
new file mode 100644
index 000000000..4dbec70cb
--- /dev/null
+++ b/blog/2026-01-16-training-inference-mismatch.md
@@ -0,0 +1,450 @@
+---
+title: "Let Speed Be With Stability: All-In-One Solution to Training-Inference Mismatch with Miles"
+author: "RadixArk, SGLang RL Team, ByteDance"
+date: "January 16, 2026"
+previewImg: /images/blog/mismatch/mismatch-preview.png
+---
+
+> TL;DR: We investigate the "Training-Inference Mismatch" in LLM-RL--a phenomenon where numerical inconsistencies between rollout and training engines threaten stability. We introduce two comprehensive solutions implemented in Miles: Truly On Policy training (backend alignment for bitwise precision) and Algorithmic Mitigation (correction via TIS/MIS). While Miles demonstrates impressive stability in practice, we provide these robust tools to ensure correctness and efficiency for the broader RL community.
+
+## Introduction
+
+The SGLang RL Team and the Miles community have recently conducted some interesting explorations around RL training stability and acceleration:
+
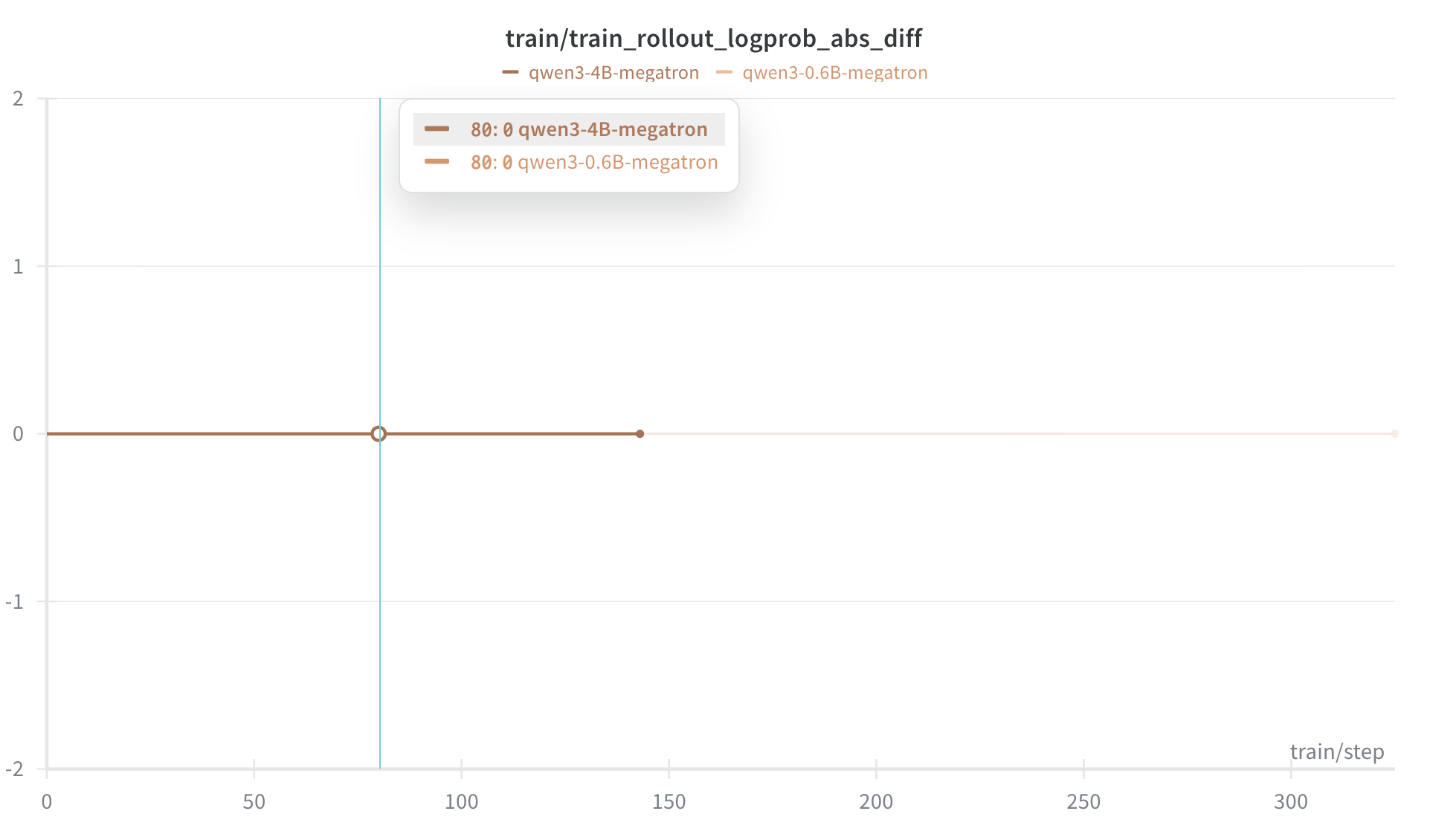
+[**Aligning the SGLang and FSDP backends for strictly zero KL divergence**](https://github.com/radixark/miles/tree/main/examples/true_on_policy): achieving perfect train–inference consistency on dense models.
+
+[**Power Up Speculative Decoding into Reinforement Learning**](https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/blob/main/rlhf/slime/spec/readme-en.md): significantly speeding up sampling under suitable configurations.
+
+[**Unified FP8: Moving Beyond Mixed Precision for Stable and Accelerated MoE RL**](https://lmsys.org/blog/2025-11-25-fp8-rl/): eliminating quantization error and improving both speed and stability of RL training.
+
+[**Support FSDP2 as A Flexible Training Backend for Miles**](https://lmsys.org/blog/2025-12-03-miles-fsdp/): adding FSDP2 as a flexible training backend to support architecture-innovative models and align with Megatron.
+
+In this post, we further discuss the first work and share our understanding of the training-inference mismatch problem and our proposed solutions.
+
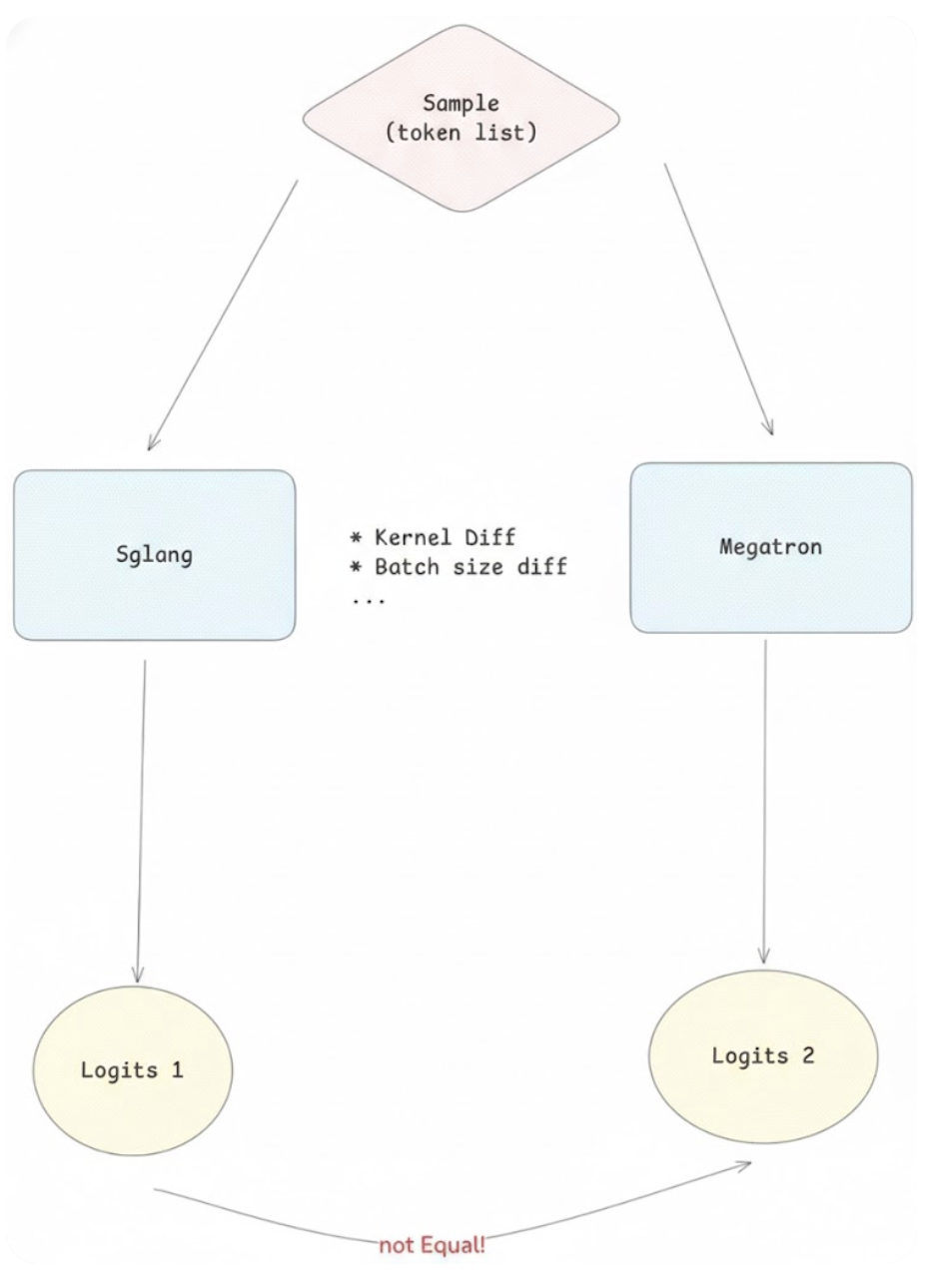
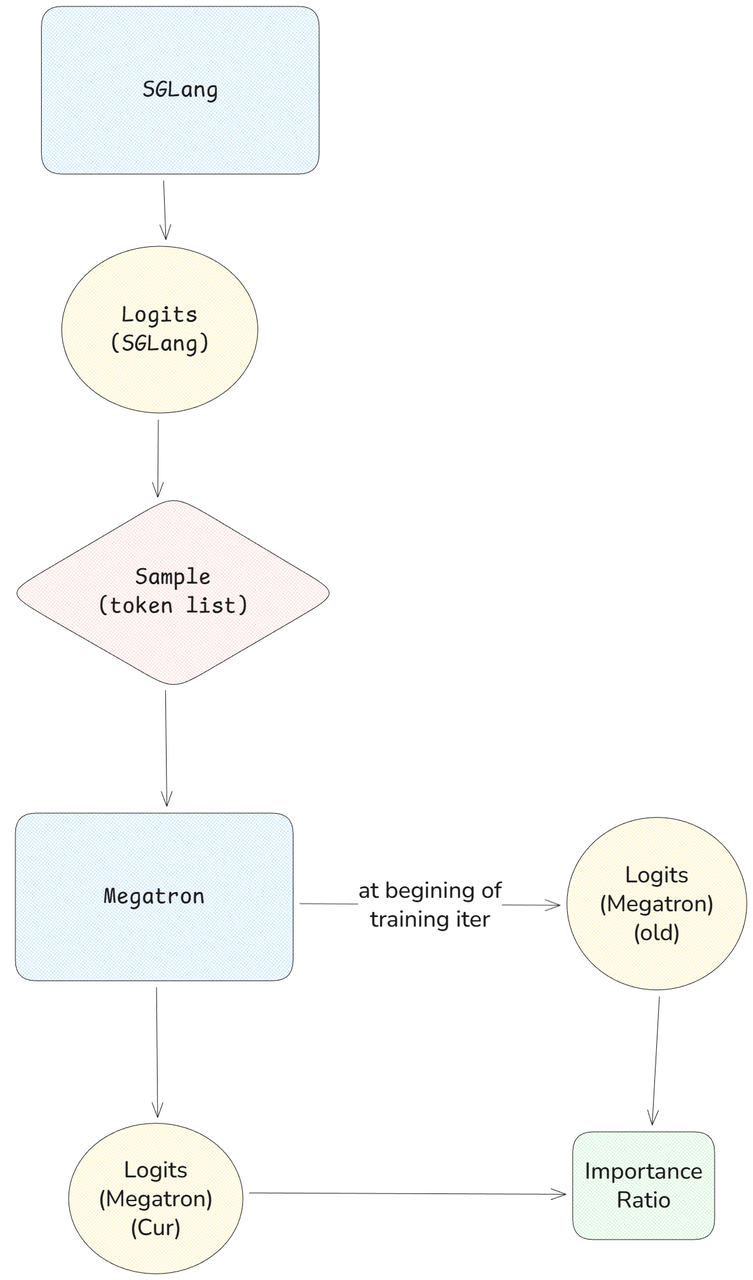
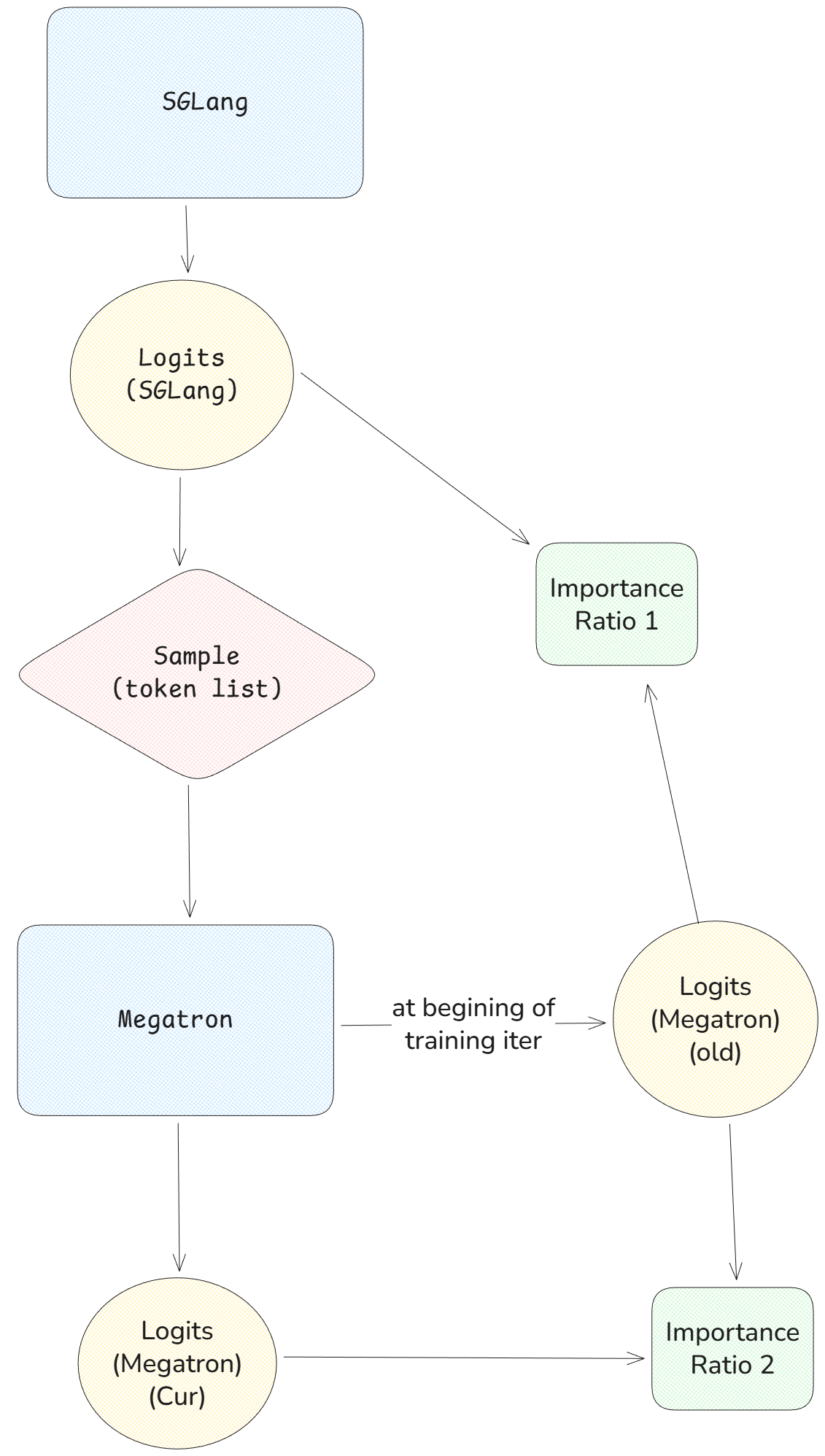
+"Training-Inference Mismatch" refers to the numerical inconsistencies that arise between the rollout (inference) engine and the training engine. Even when utilizing identical model weights, these engines often produce divergent log-probabilities for the same token sequence. In this post, we analyze the root causes of this divergence and present Miles' dual-approach solution.
+
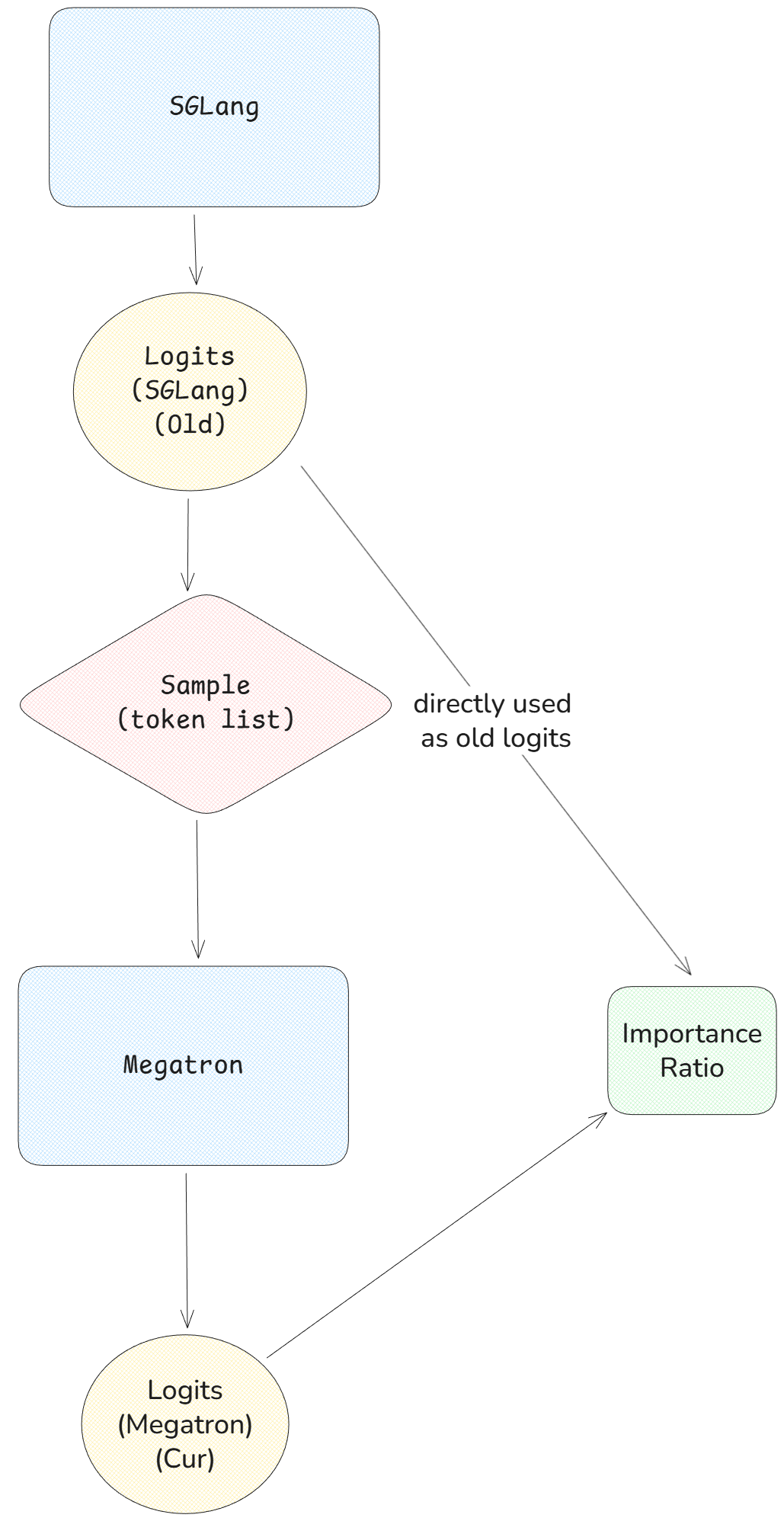
+For those seeking absolute correctness, we offer a [Truly On Policy mode](https://github.com/radixark/Miles/blob/main/examples/true_on_policy/README.md) that achieves bitwise-exact alignment between SGLang and FSDP/Megatron. For those prioritizing throughput, we provide Algorithmic Mitigation strategies, such as [Masked Importance Sampling (MIS)](https://richardli.xyz/rl-collapse-3) and [Truncated Importance Sampling (TIS)](https://fengyao.notion.site/off-policy-rl#279721e3f6c48092bbe2fcfe0e9c6b33). Our experiments demonstrate that MIS effectively suppresses mismatch growth during late-stage training while preserving high performance, making it a robust default for RL practitioners.
+
+## What is Training Inference Mismatch?
+
+
+
+
+
+
+
+
+
+
+
+
+
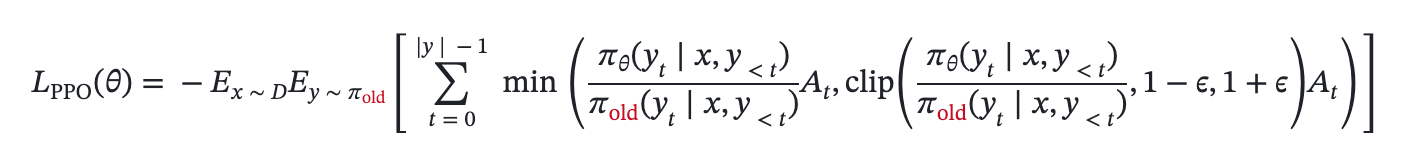
+
+
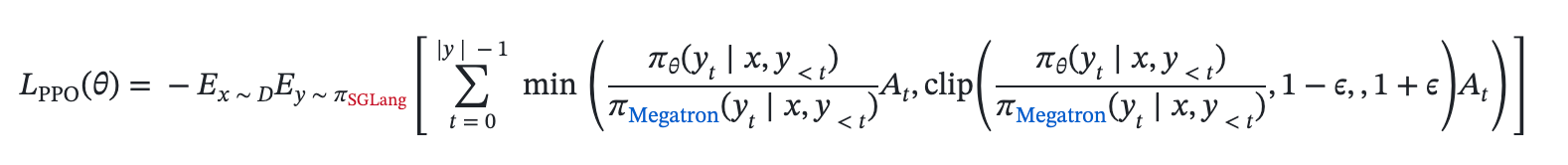
+
+
+
+
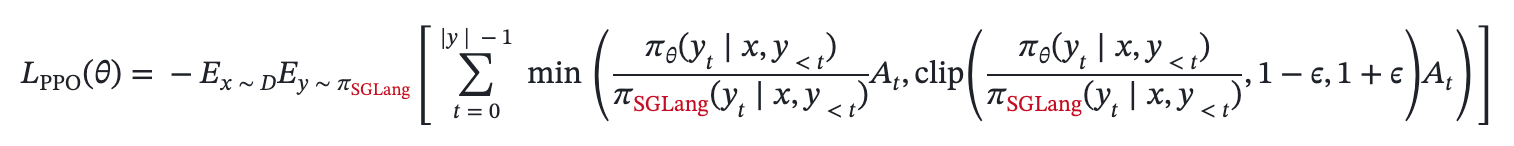
+
+
+
+
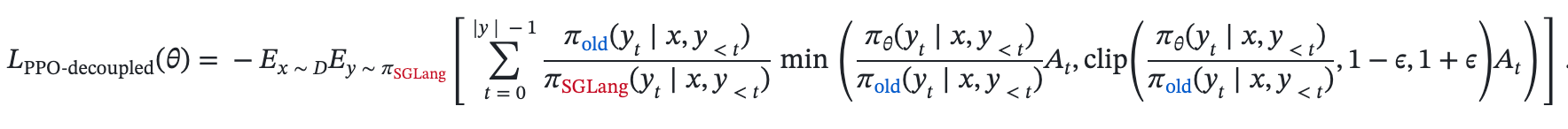
+
+
+
+  +
+  +
+
+
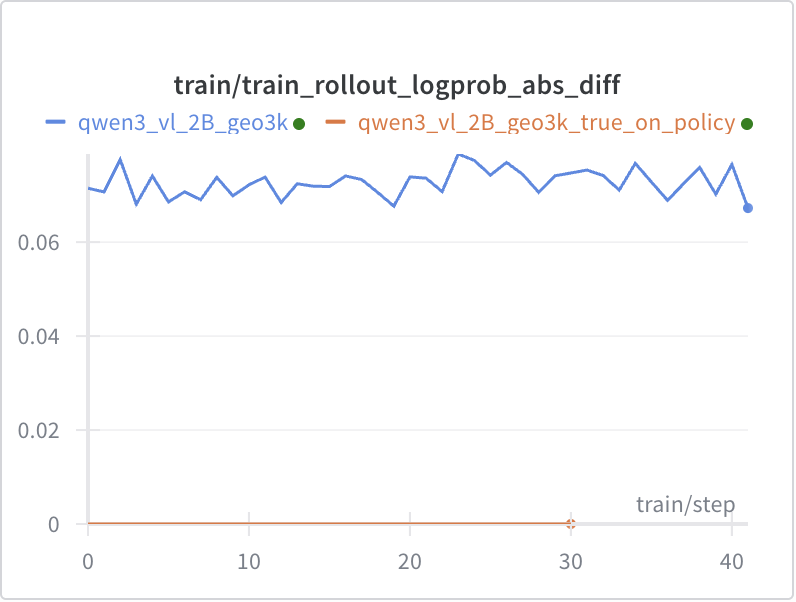
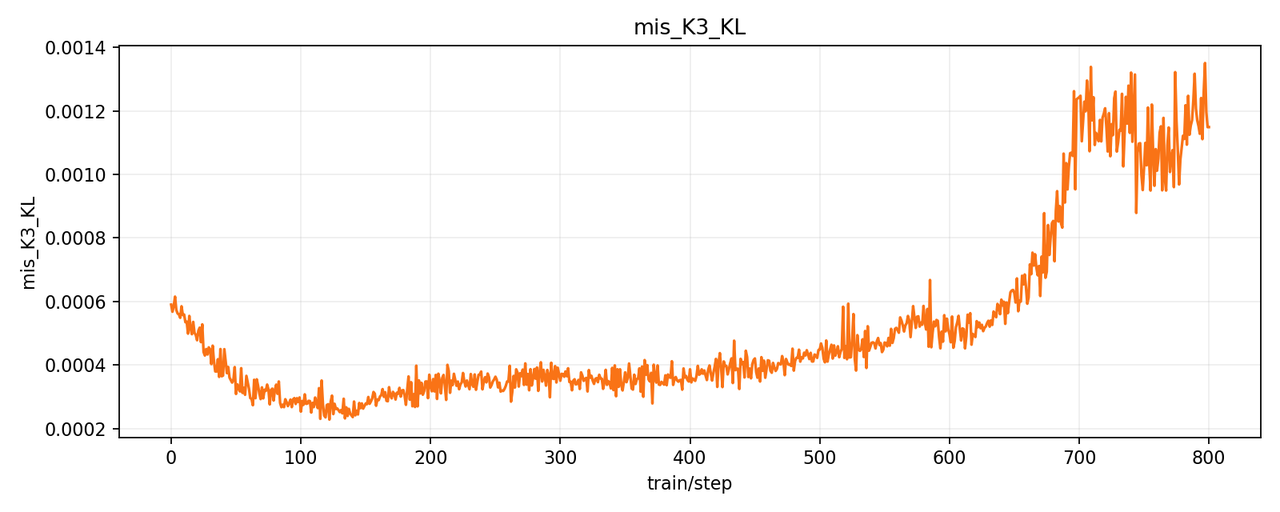
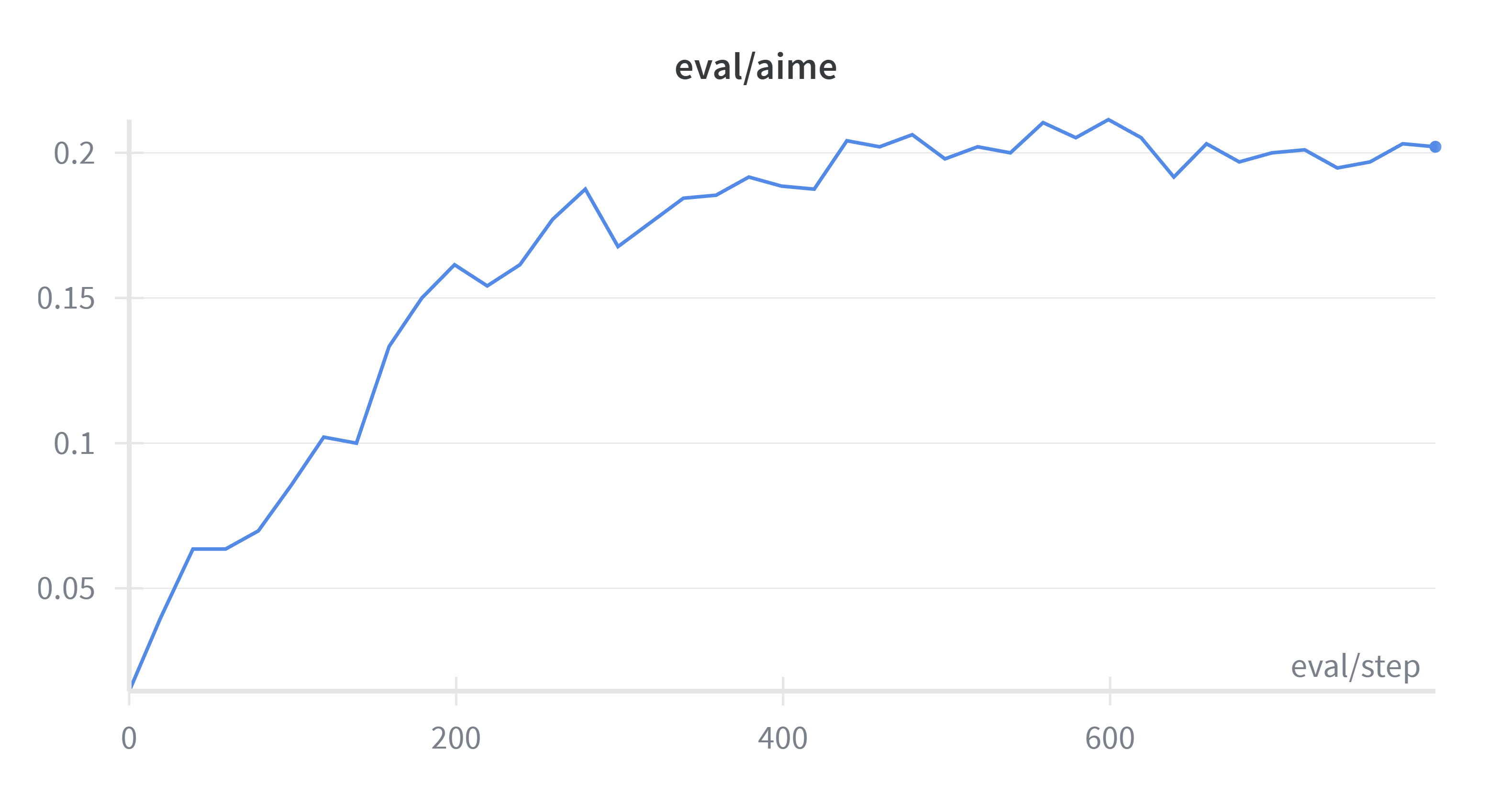
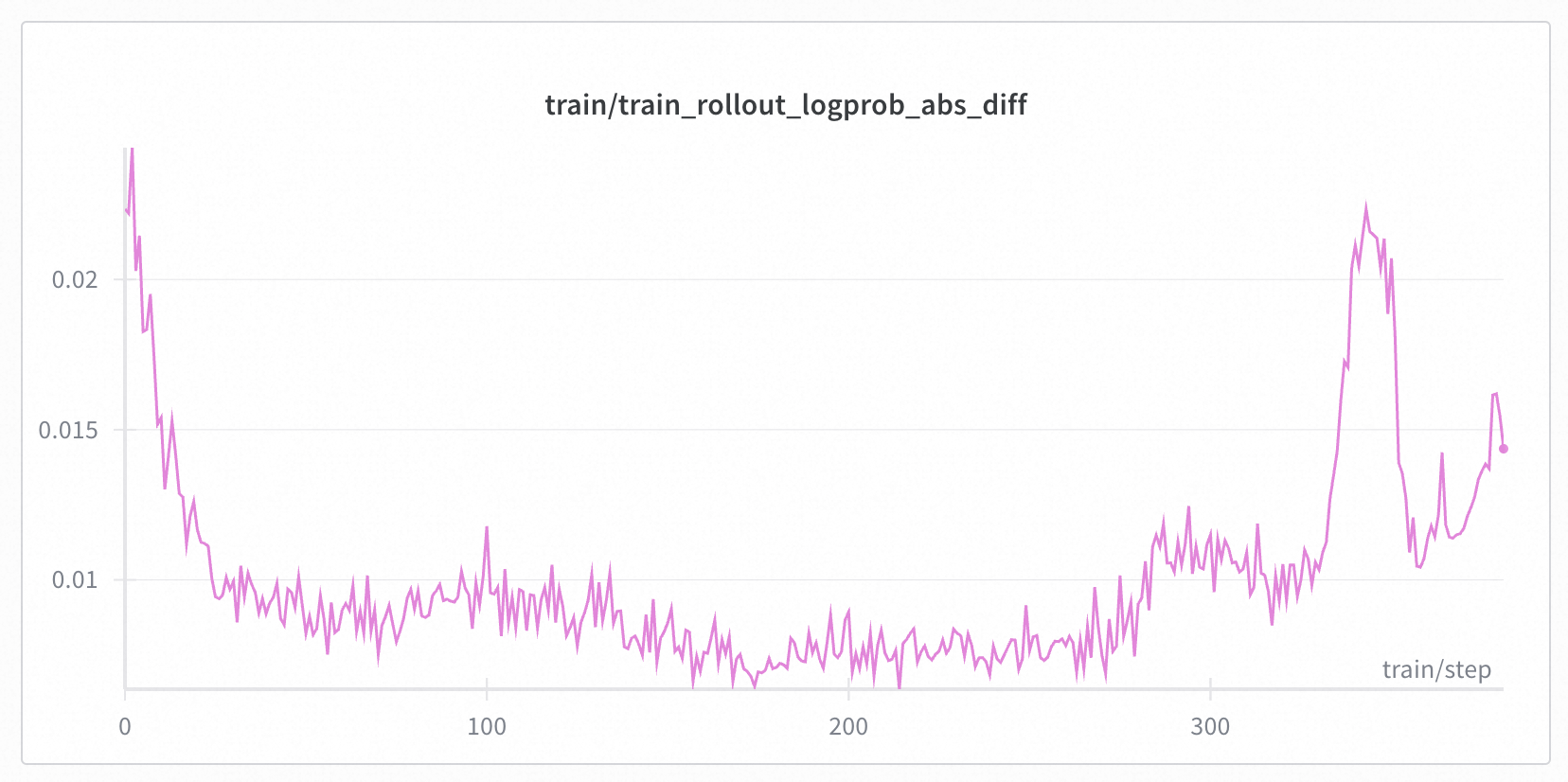
+You can see in the initial step of training, as the model learns and perplexity drops, K3 KL actually drops. But after 600 steps, although the train and eval reward remains stable, the K3 KL metrics start to increase dramatically, indicating the existence of training and rollout mismatch.
+
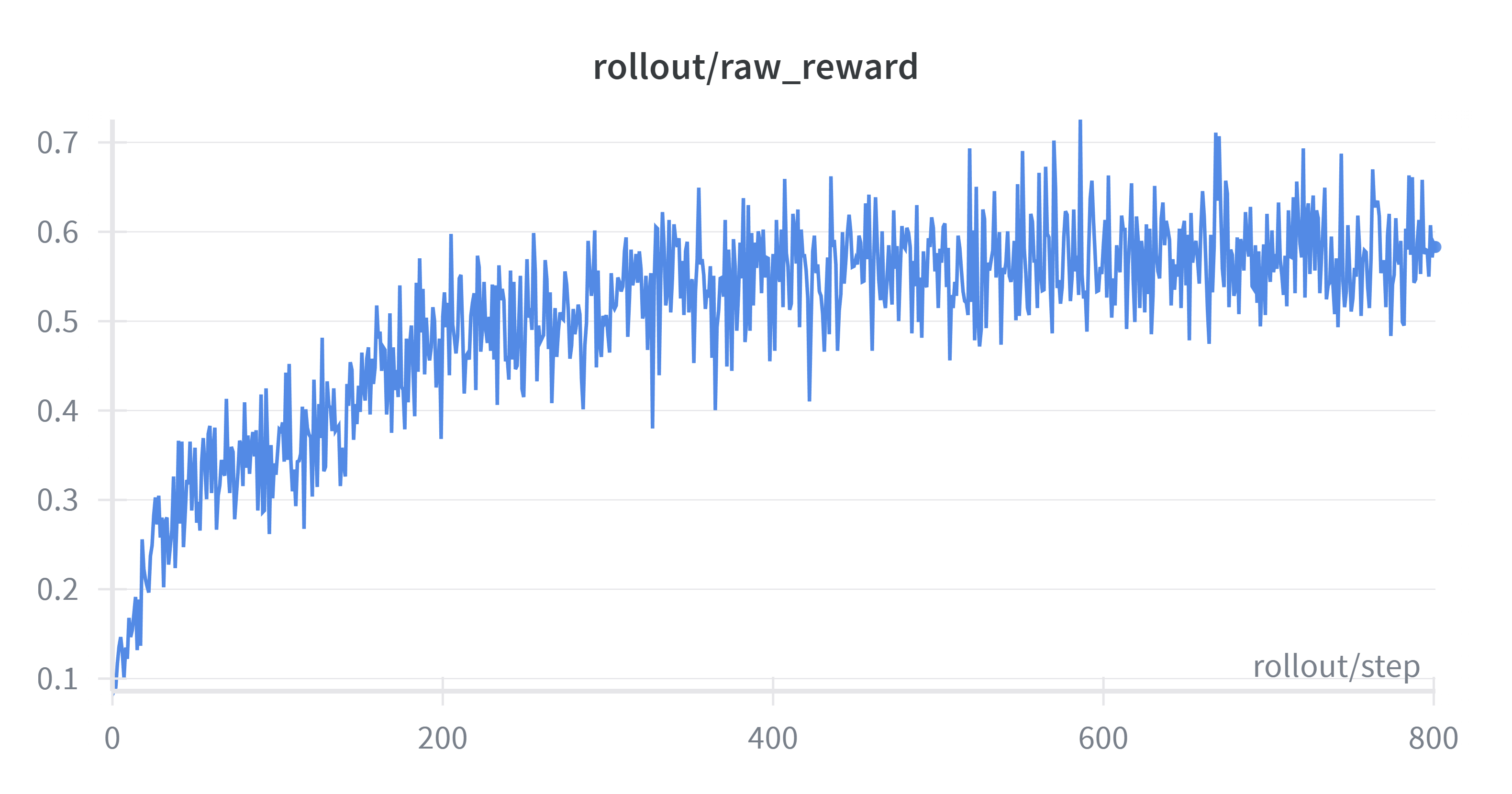
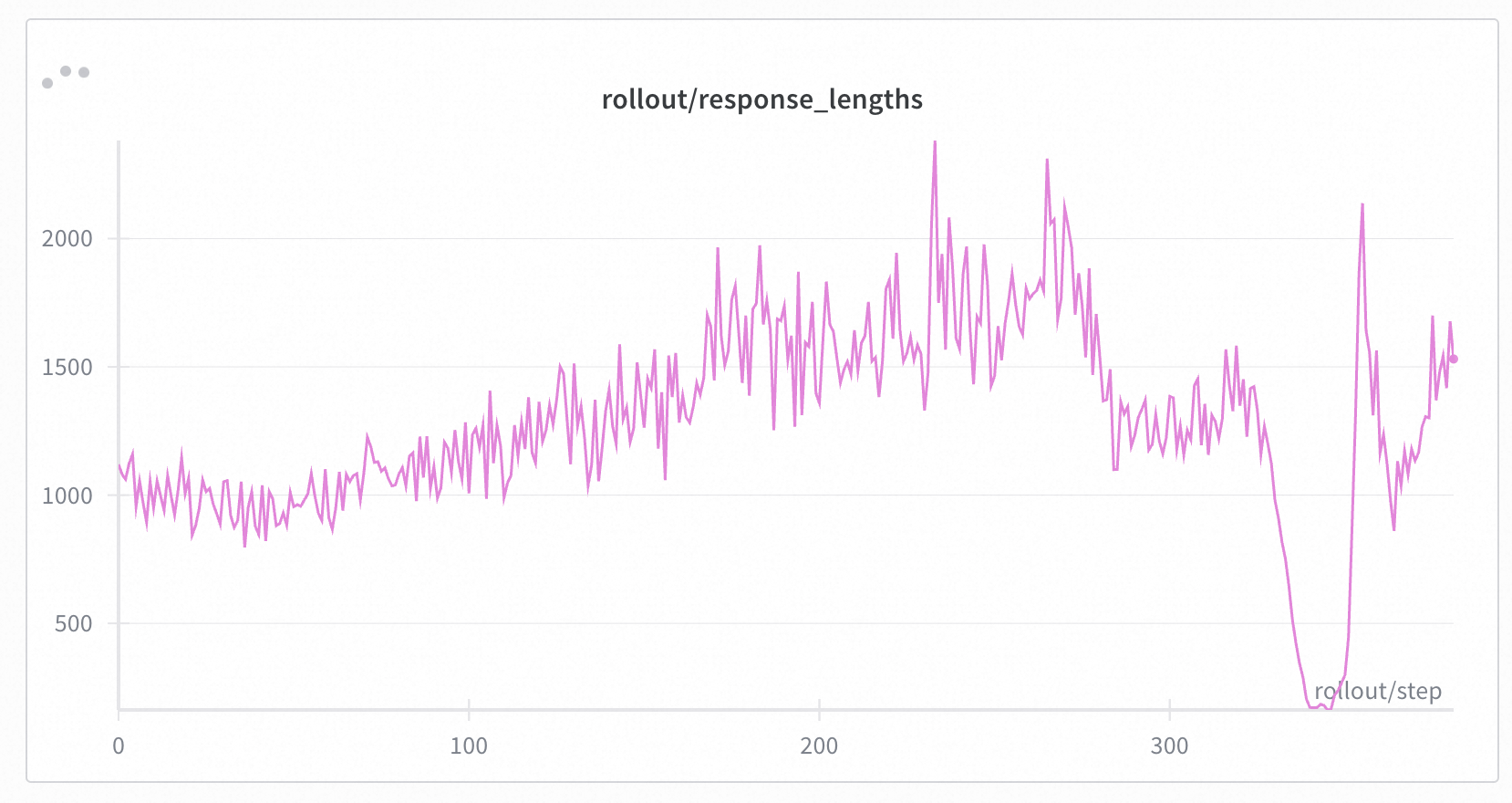
+On MoE models, the diff in logits causes the training and inference models to select different activated experts, leading to significantly larger train-inference mismatch in MoE models compared to dense models (although on Qwen30B-A3B, when not collapsed, the magnitude of K3 KL is similar to Qwen3-4B, possibly). We successfully found cases where models collapse due to train-inference mismatch (experimental settings are the same as dense models except for the base model). Below are some specific experimental results.
+
+
+
+
+
+
+
+
+
+More metrics on MoE experiments
+
+
+
+
+
+
+
+
+
+
+
+
+### When Mismatch is Small, IS Won't Harm Performance
+
+> Full wandb log for Qwen3-4B-Base can be found [here](https://wandb.ai/ch271828n-team/slime-dapo/reports/IS-Has-No-Harm--VmlldzoxNTE3NTM3MQ).
+
+In our Qwen3-4B-Base experiments, we verified that enabling TIS/MIS (including several commonly used configurations) does not degrade performance or destabilize training. To demonstrate this, we enabled different IS-related options at the beginning of training and compared them against a baseline with no IS correction.
+Below are the four configurations we evaluated:
+
+1. Baseline
+2. Token-level Importance Sampling(IS)
+3. Token-level IS + Sequence Masking/Rejection Sampling(RS) [a.k.a [MIS](https://richardli.xyz/rl-collapse-3)]
+4. Token-level IS + Sequence Masking/Rejection Sampling(RS) + Batch Normalization(BN) [a.k.a [MIS](https://richardli.xyz/rl-collapse-3)]
+
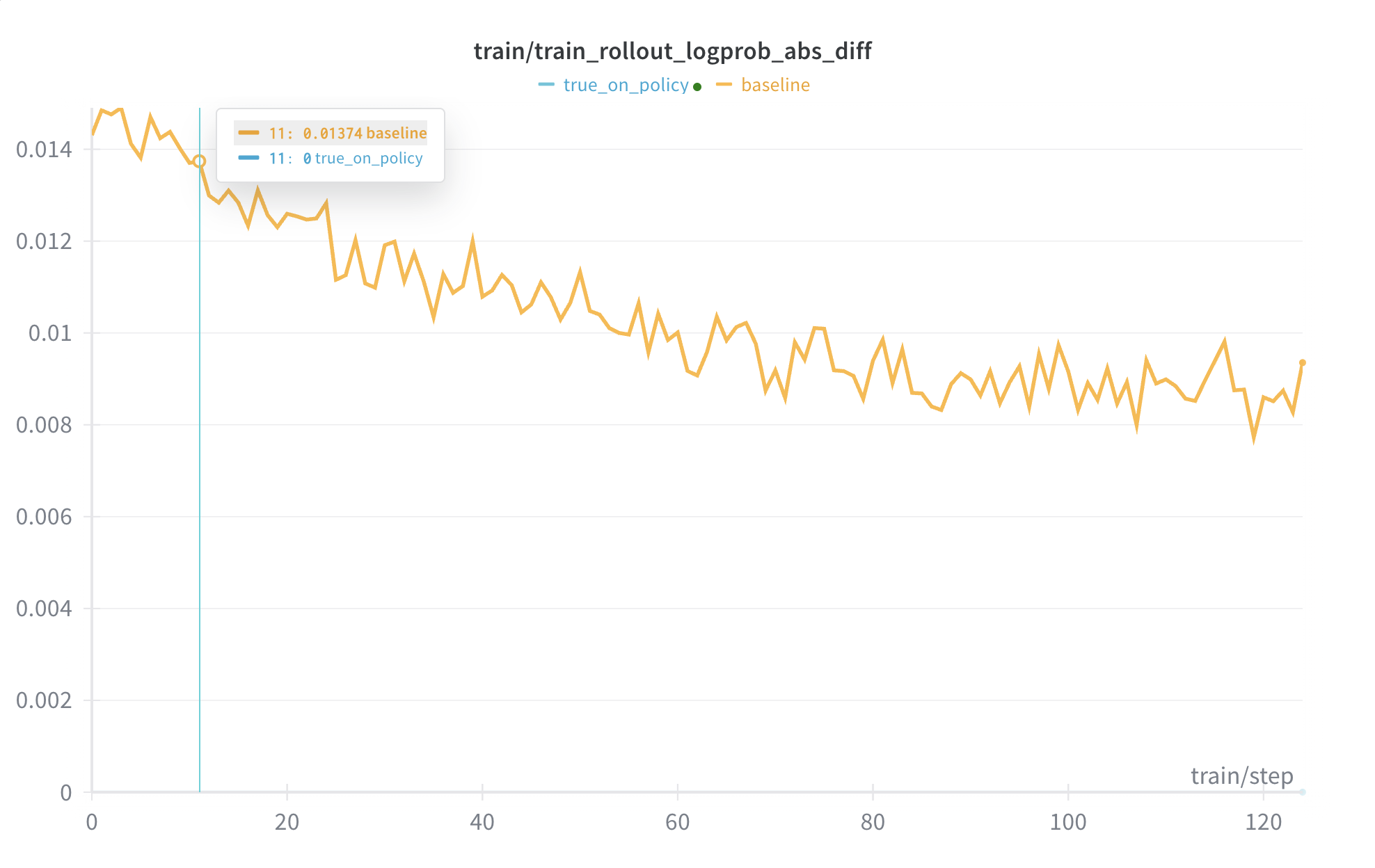
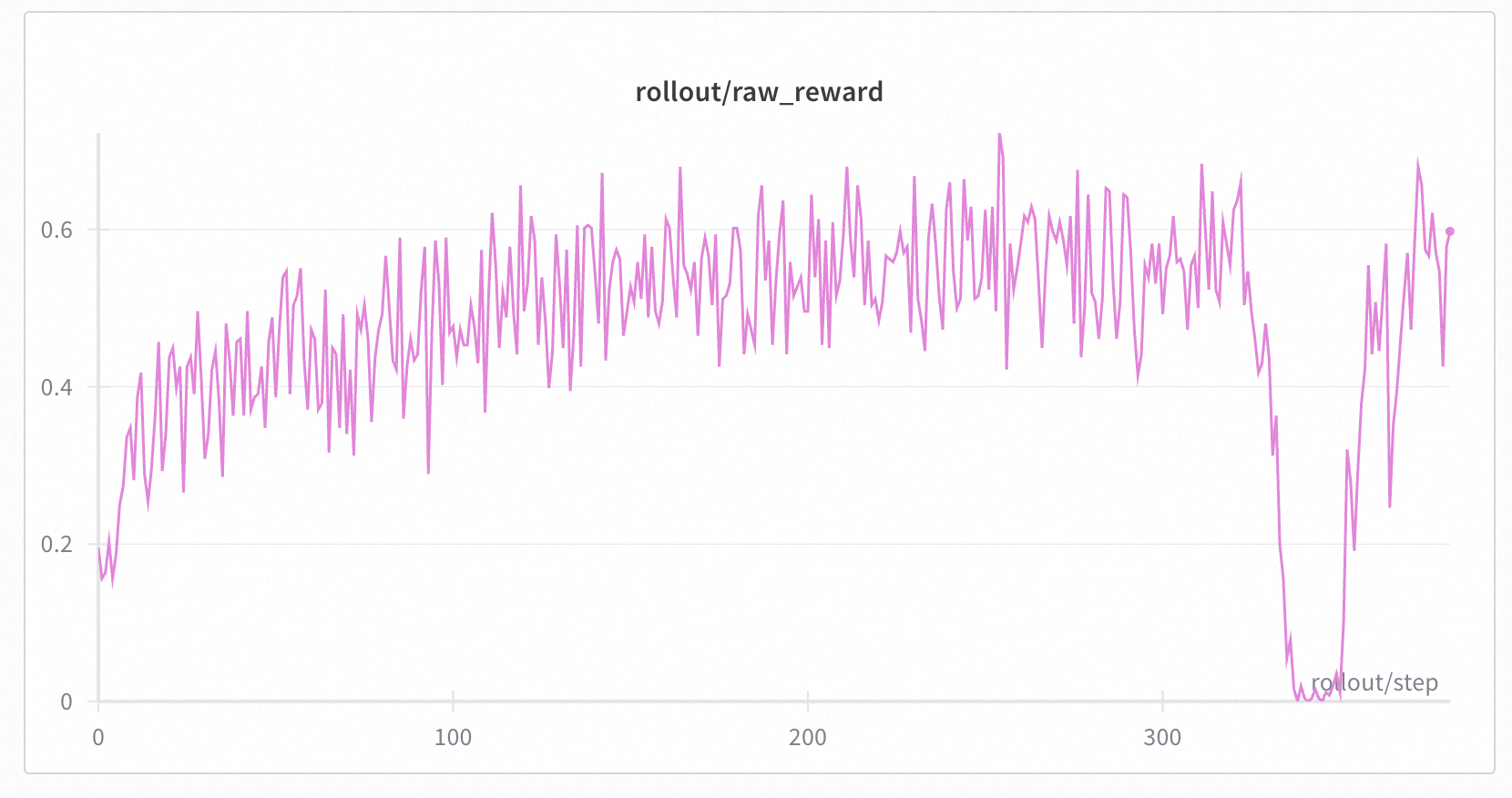
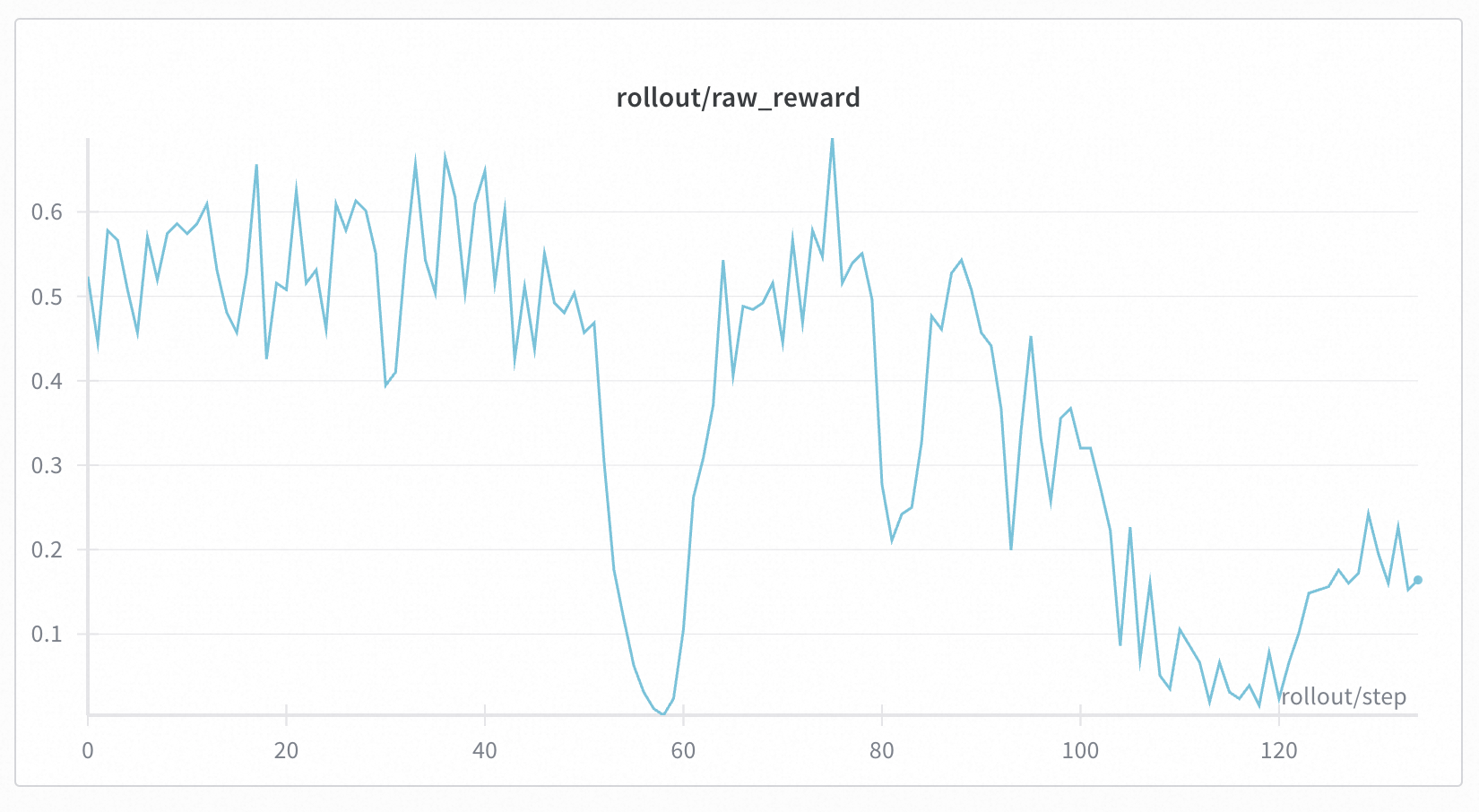
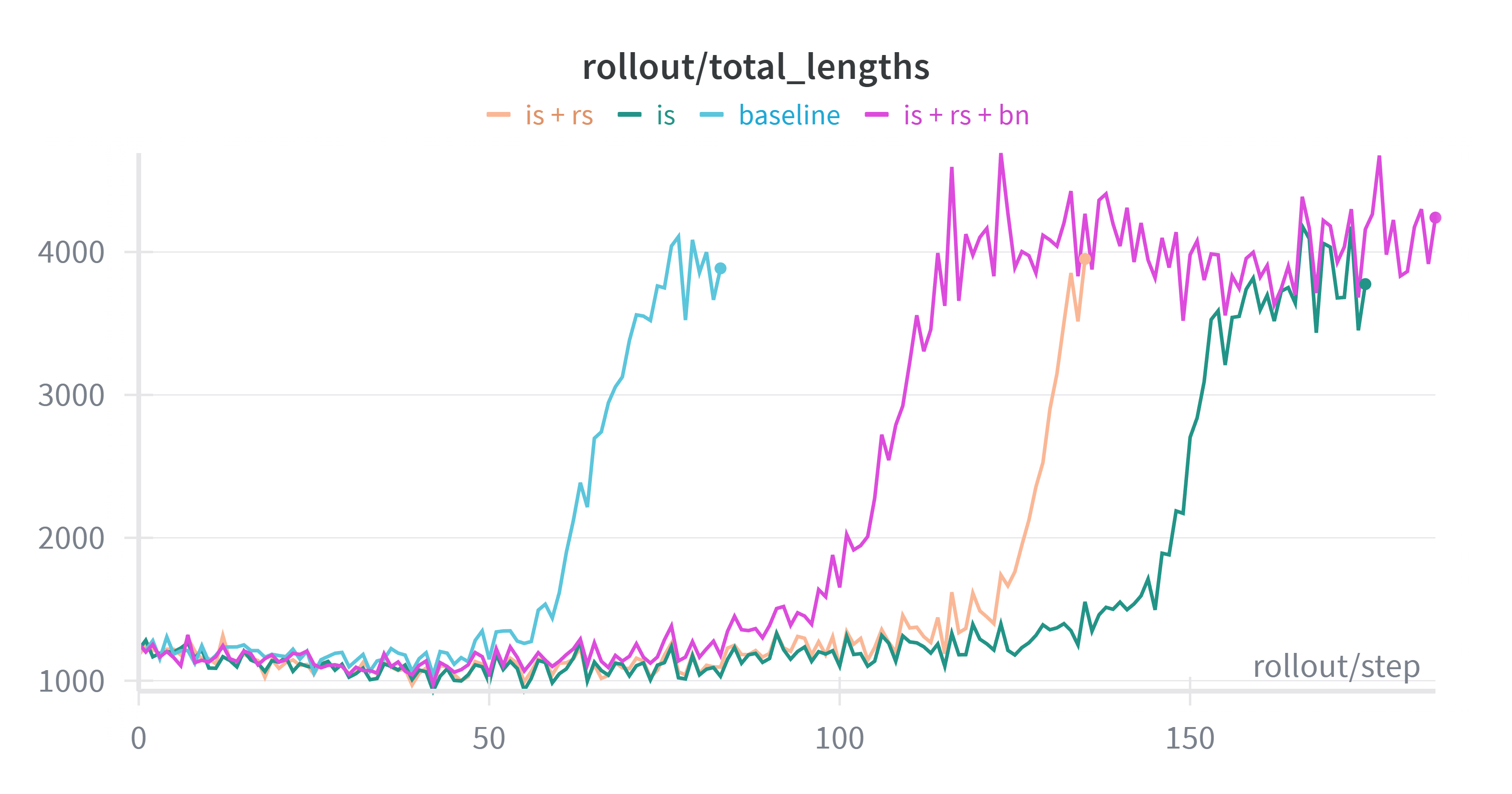
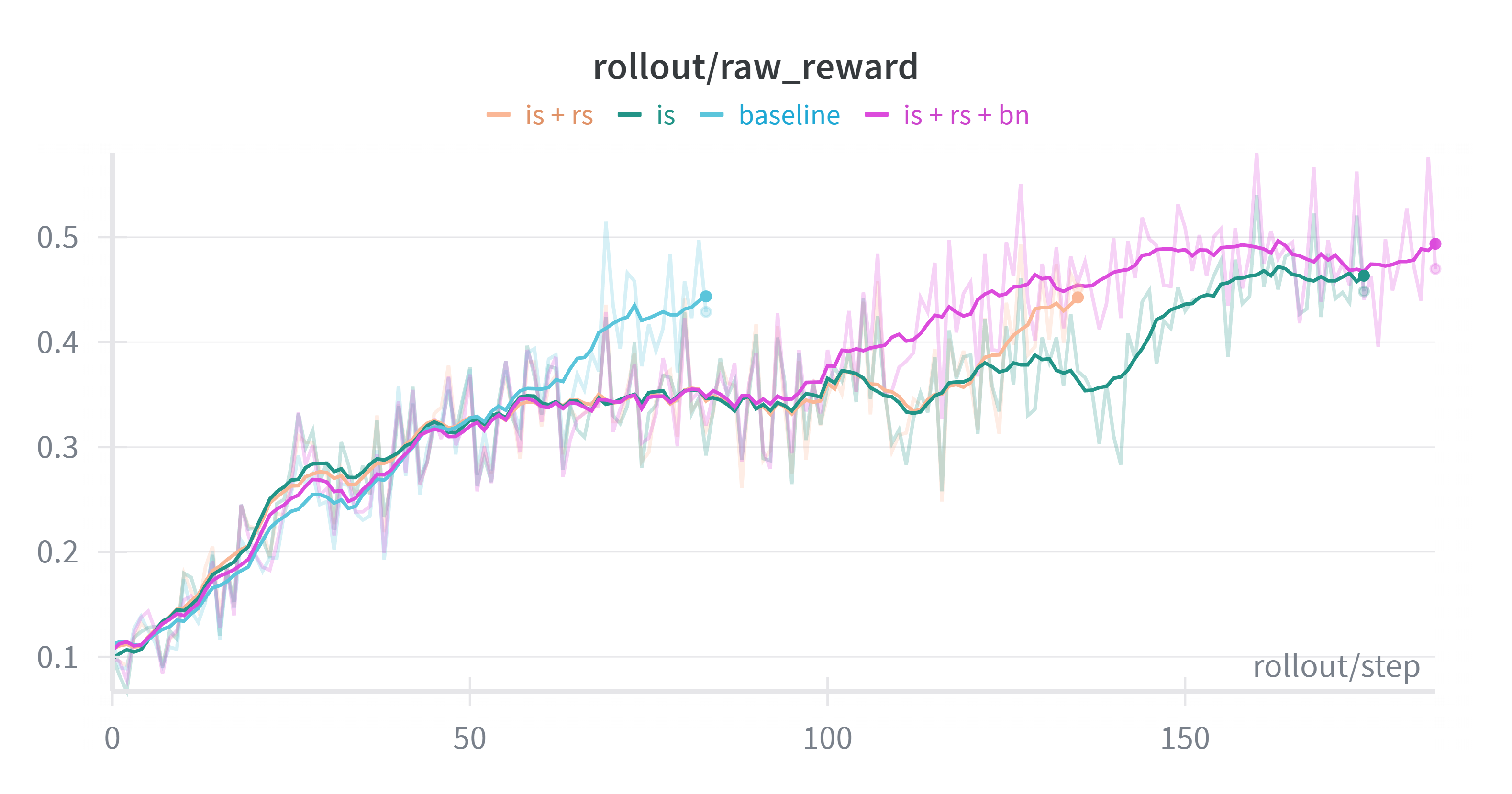
+Across all settings, we consistently observed stable training curves. All four configurations successfully reproduced the characteristic length increase after ~100 steps, indicating that enabling IS does not negatively impact the learning dynamics. Additionally, across all experiments, the reward begins to improve only after the response length starts to increase; prior to this, the reward stagnates around 0.32. Based on these results, we recommend enabling IS as a default configuration, as it provides mismatch correction without sacrificing performance.
+
+
+
+
+
+ Left: Response Length. Right: Raw Reward (smoothed with moving average).
+
+
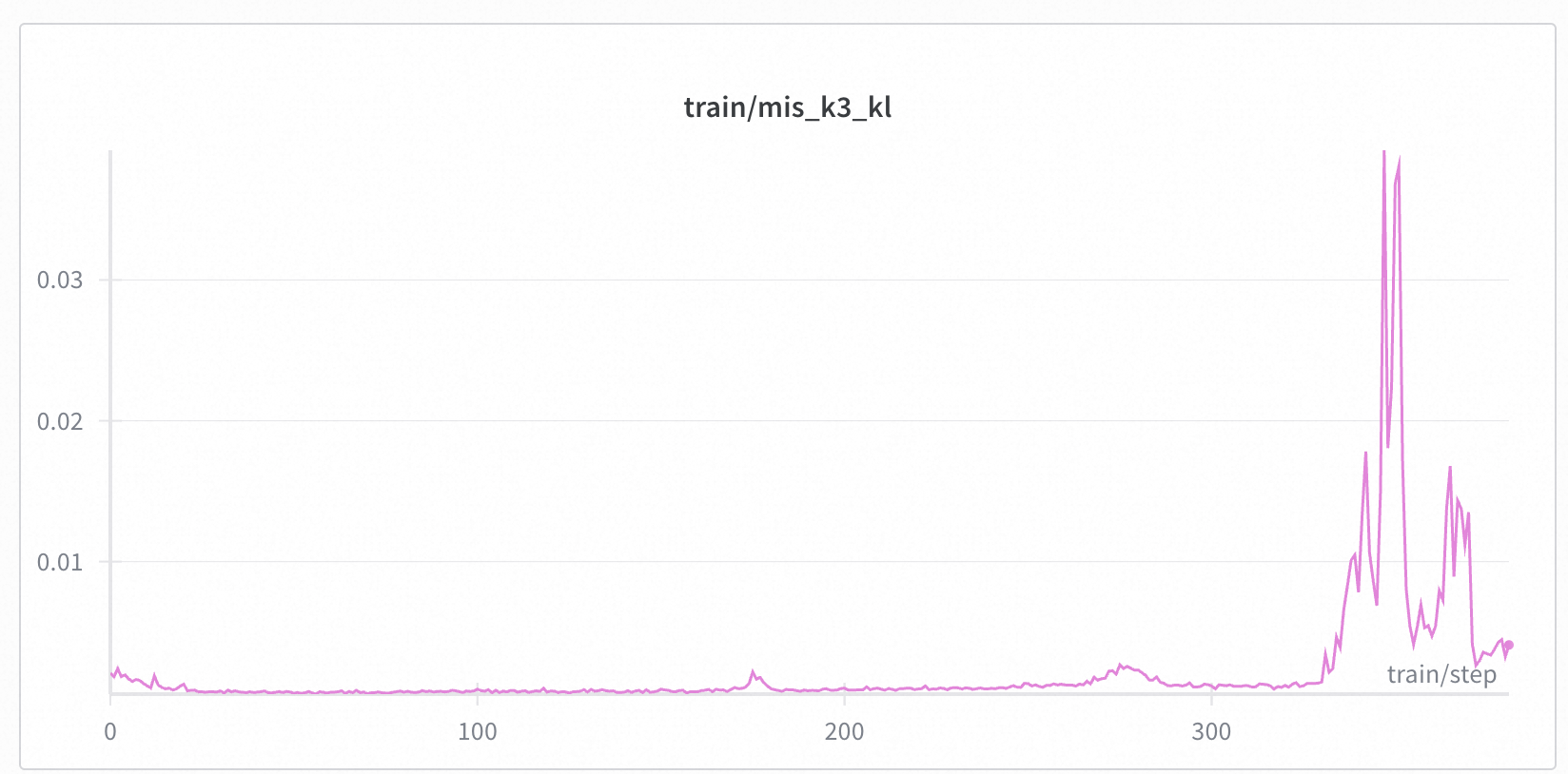
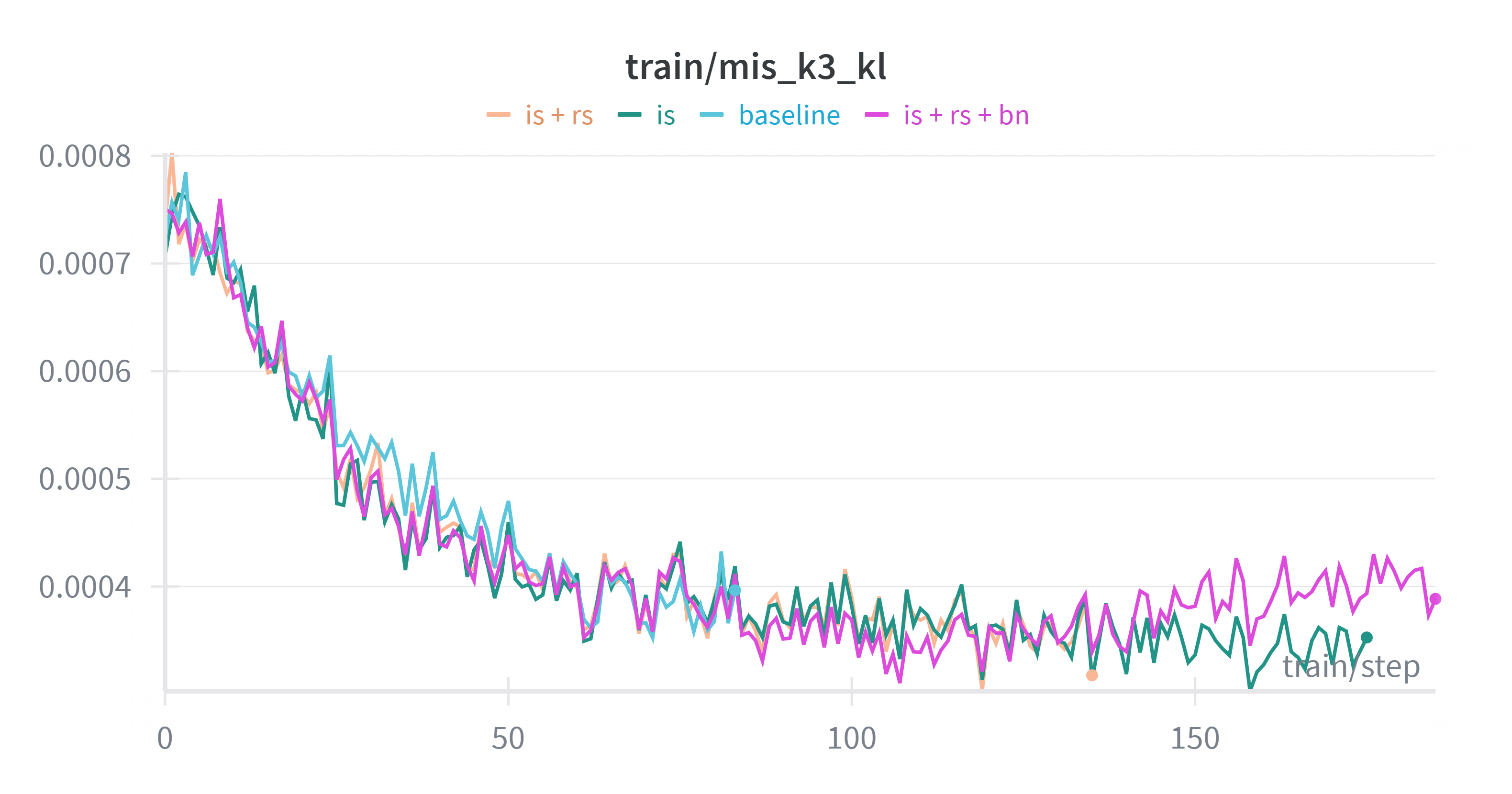
+We also examined the K3 KL divergence for these runs. We observed that across all settings, as the training perplexity (PPL) decreases, the training-inference mismatch (measured by K3 KL) also diminishes, which is consistent with our long base run above.
+
+
+
+
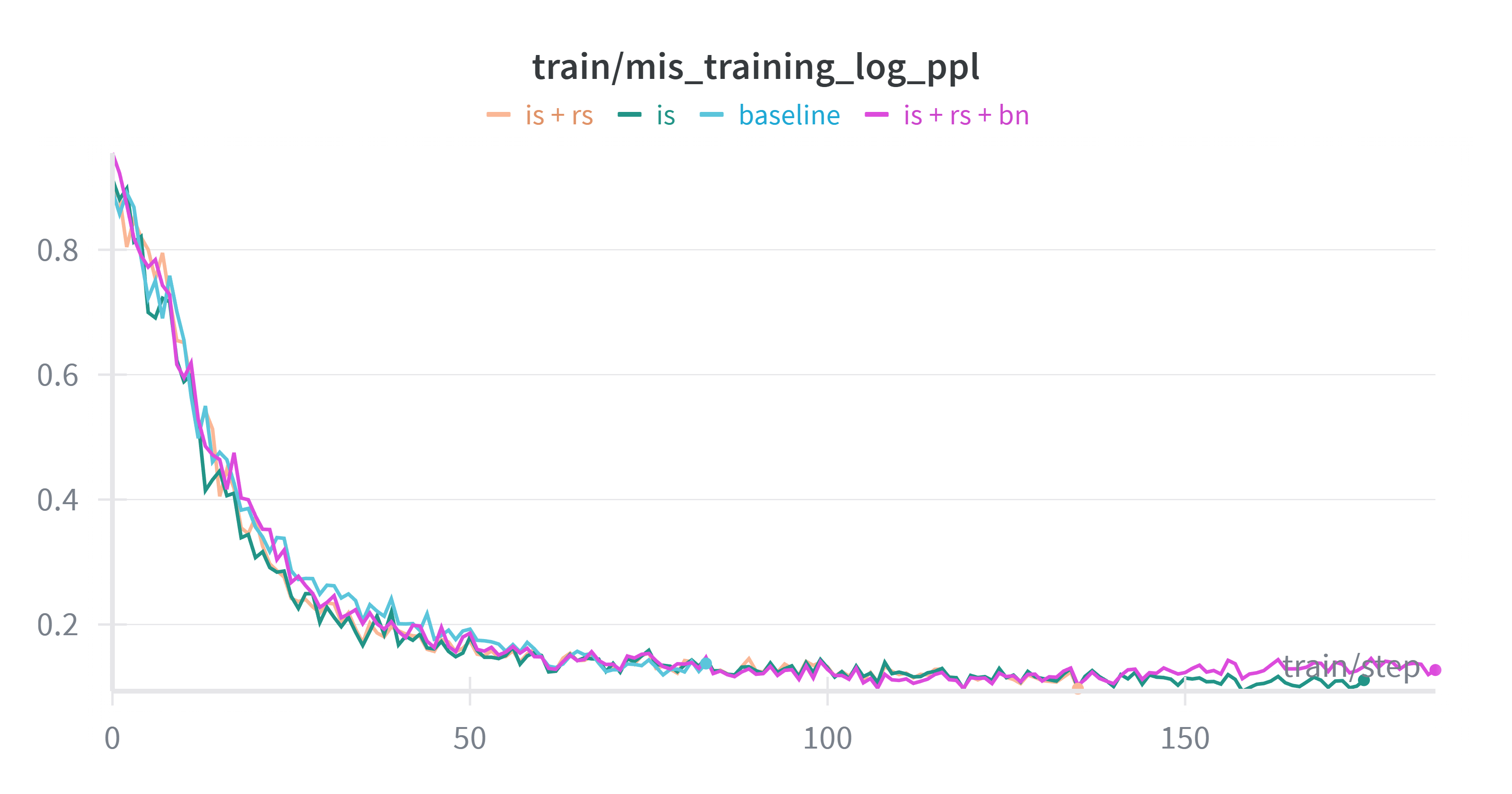
+
+ Left: K3 KL Divergence. Right: Training Perplexity (PPL).
+
+
+### When Mismatch is Large, TIS/MIS Can Solve Collapse
+
+> Full wandb log for Qwen30B-A3B can be found [here](https://wandb.ai/miles-public/slime-dapo/reports/Training-inference-Mismatch-MoE-Experiement--VmlldzoxNTYzMTYxOQ?accessToken=p1dohuhn8vtlr9tddxhnjjdtkzwce0mzeat14ehxj3r96cz15sp5f1yxz0qo0qbn)
+>
+> ckpt address can be found here [here](https://huggingface.co/collections/zhuohaoli/qwen3-30b-a3b-base-mismatch)
+
+
+
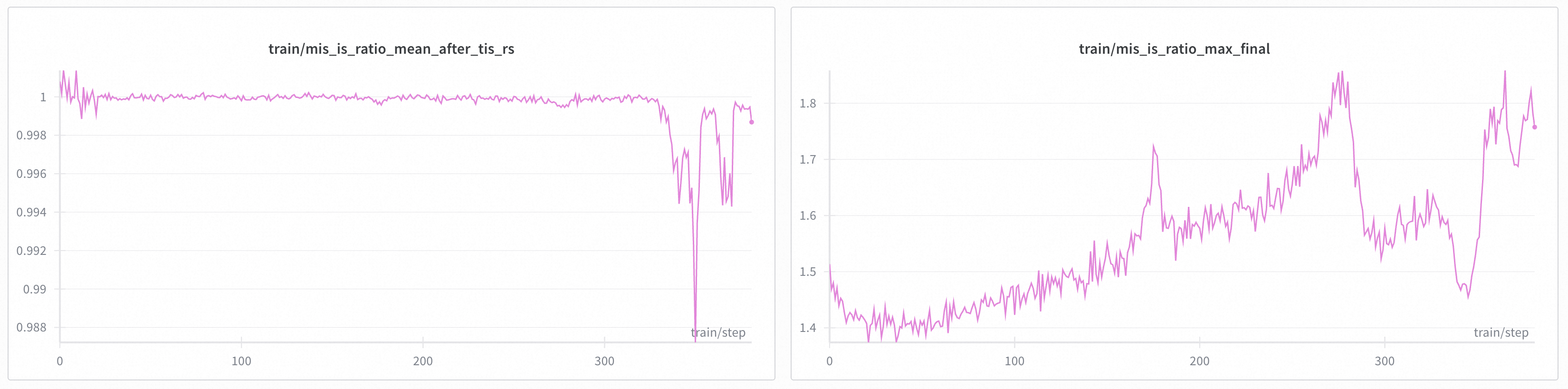
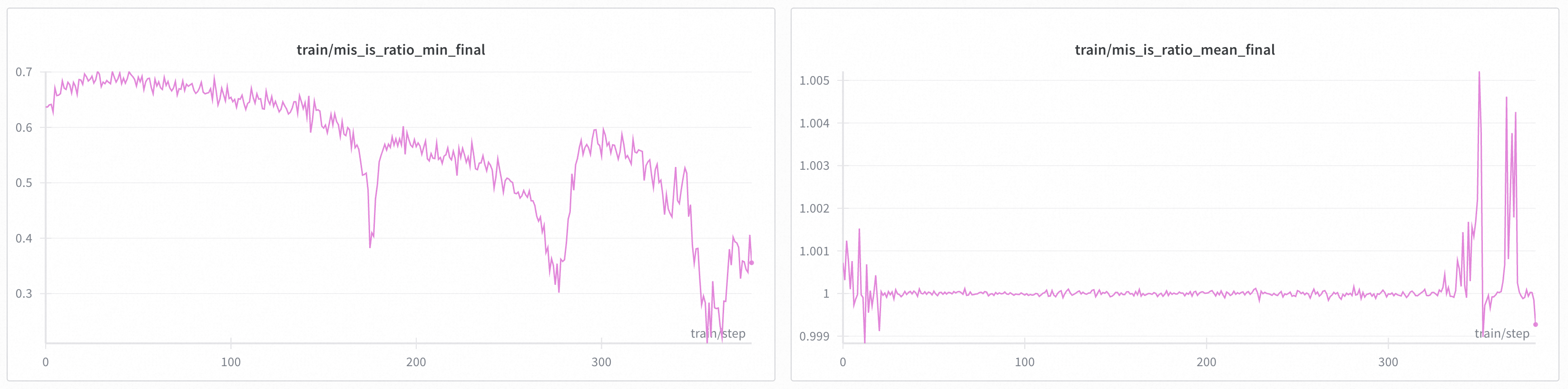
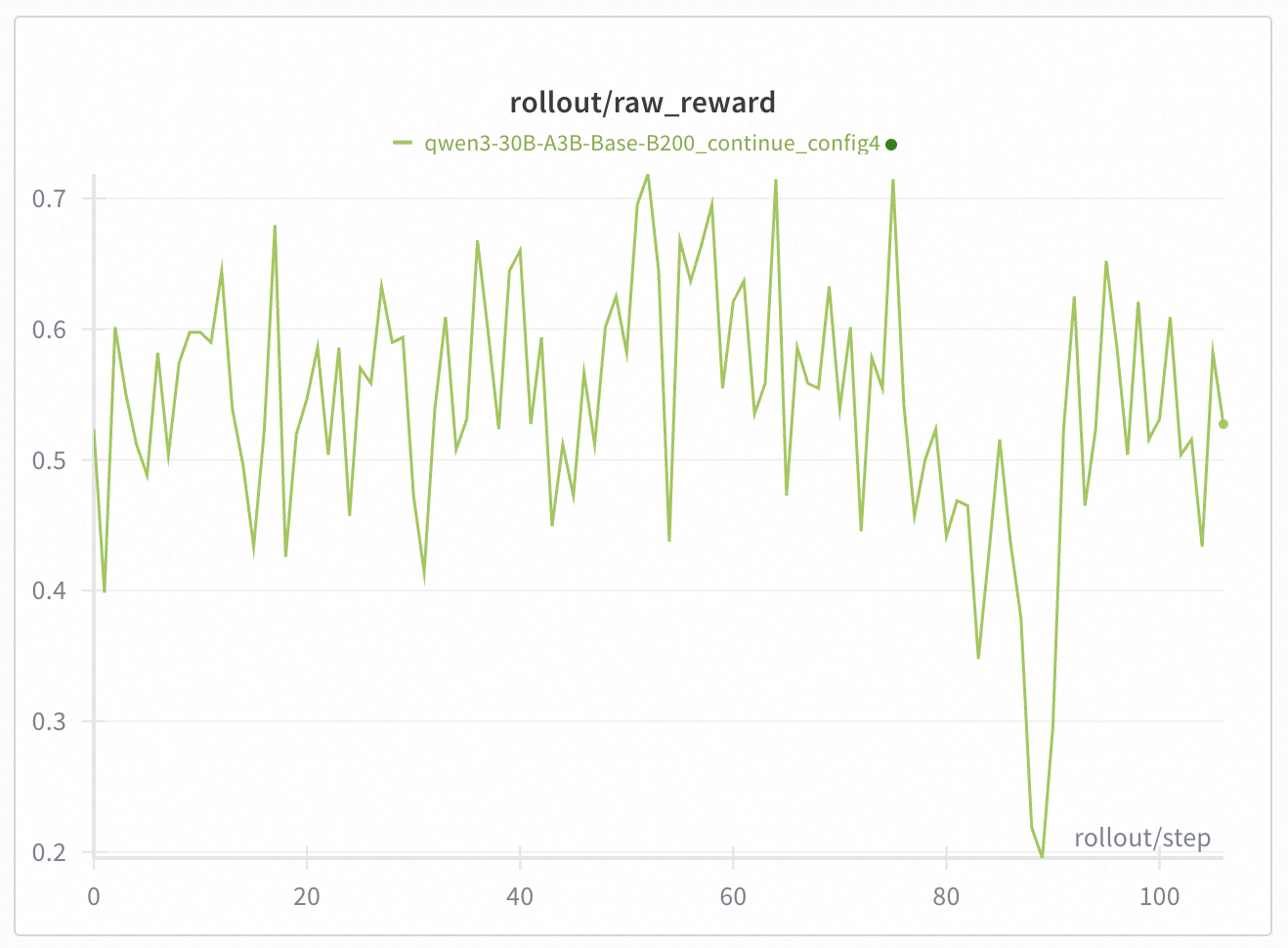
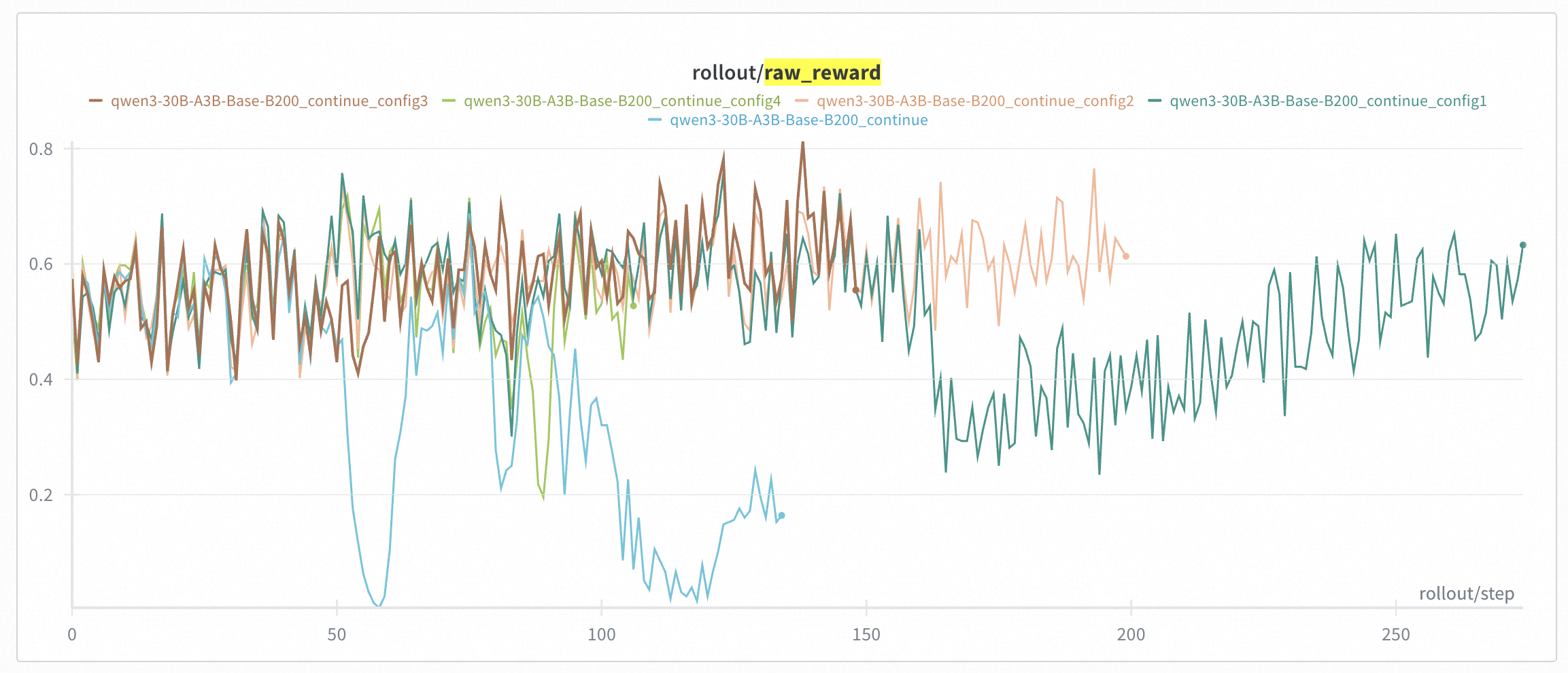
+In Qwen30B-A3B, we took a 300 steps checkpoint (i.e. [Base-DRPO-original](https://huggingface.co/zhuohaoli/Qwen3-30B-A3B-Base-DRPO-original)) and continued training with different TIS/MIS settings. We found that properly configured TIS + MIS can effectively suppress collapse caused by train-inference mismatch. We conducted experiments with 4 different settings:
+
+* config 1: token TIS [0.5, 2.0] + geometric MIS [0.99, 1.001] + batch norm --> still collapsed
+* config 2: token TIS [0.5, 1.5] + geometric MIS [0.99, 1.001] + batch norm --> did not collapse
+* config 3: token TIS [0.5, 1.5] + geometric MIS [0.99, 1.001] --> did not collapse
+* config 4: token TIS [0.5, 1.5] --> collapsed
+
+
+More other configurations could be found below
+
+| Category | Setting | Value |
+| --- | --- | --- |
+| Batch | global-batch-size | 256 |
+| Batch | rollout-batch-size | 32 |
+| Optimizer | lr | 2e-6 |
+| Optimizer | weight-decay | 0.01 |
+| Optimizer | adam-betas | (0.9, 0.999) |
+| Parallel | tensor-model-parallel-size | 4 |
+| Parallel | expert-model-parallel-size | 8 |
+| Memory | max-tokens-per-gpu | 20480 |
+| Rollout/Eval | num-rollout | 3000 |
+| Rollout/Eval | n-samples-per-prompt | 8 |
+| Rollout/Eval | n-samples-per-eval-prompt | 16 |
+| Rollout/Eval | max-response-len (rollout/eval) | 16384 / 16384 |
+
+
+
+Note that on these figures, the start step is 0, but they are indeed a 300 steps checkpoint.
+
+
+
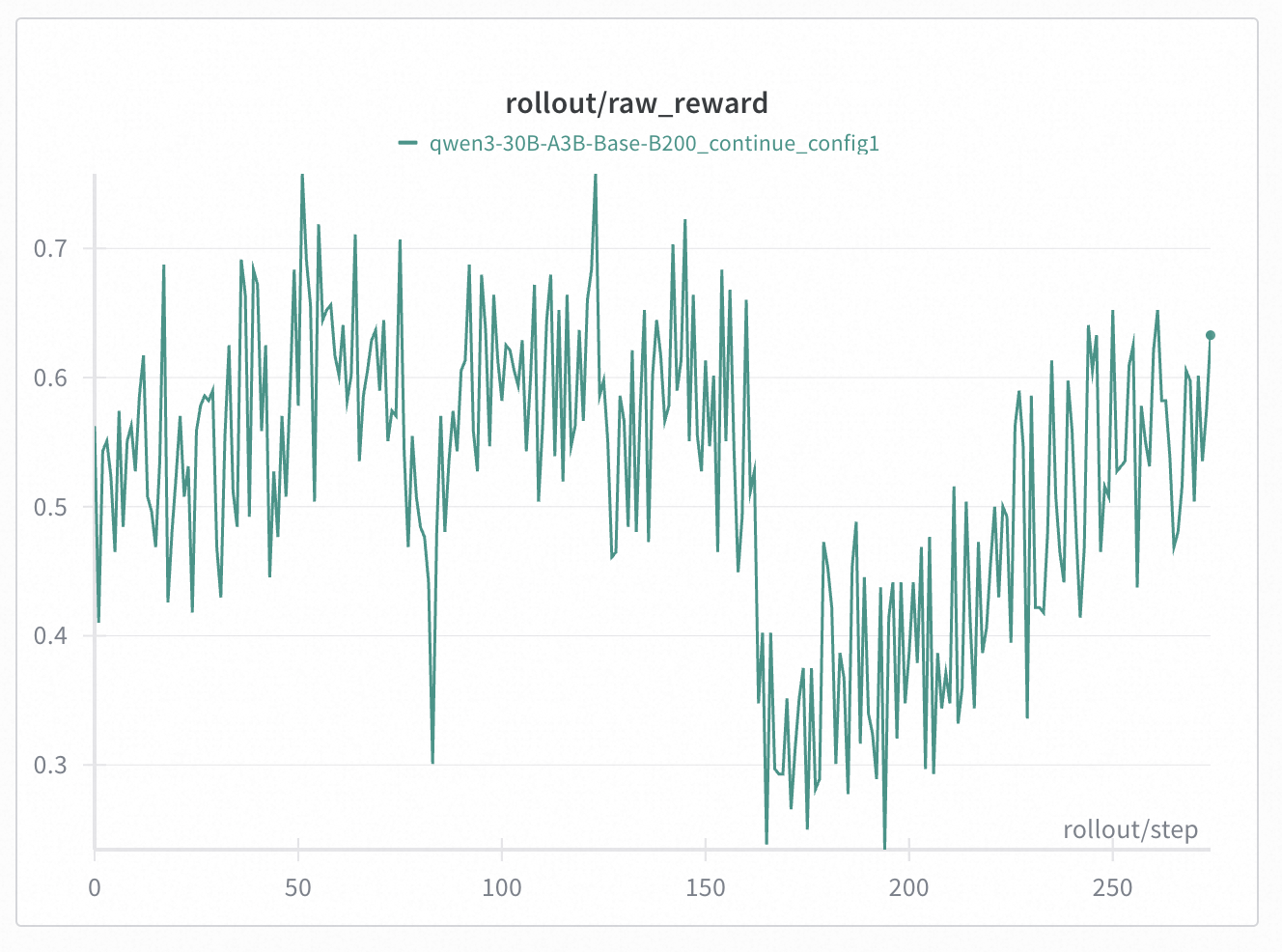
+
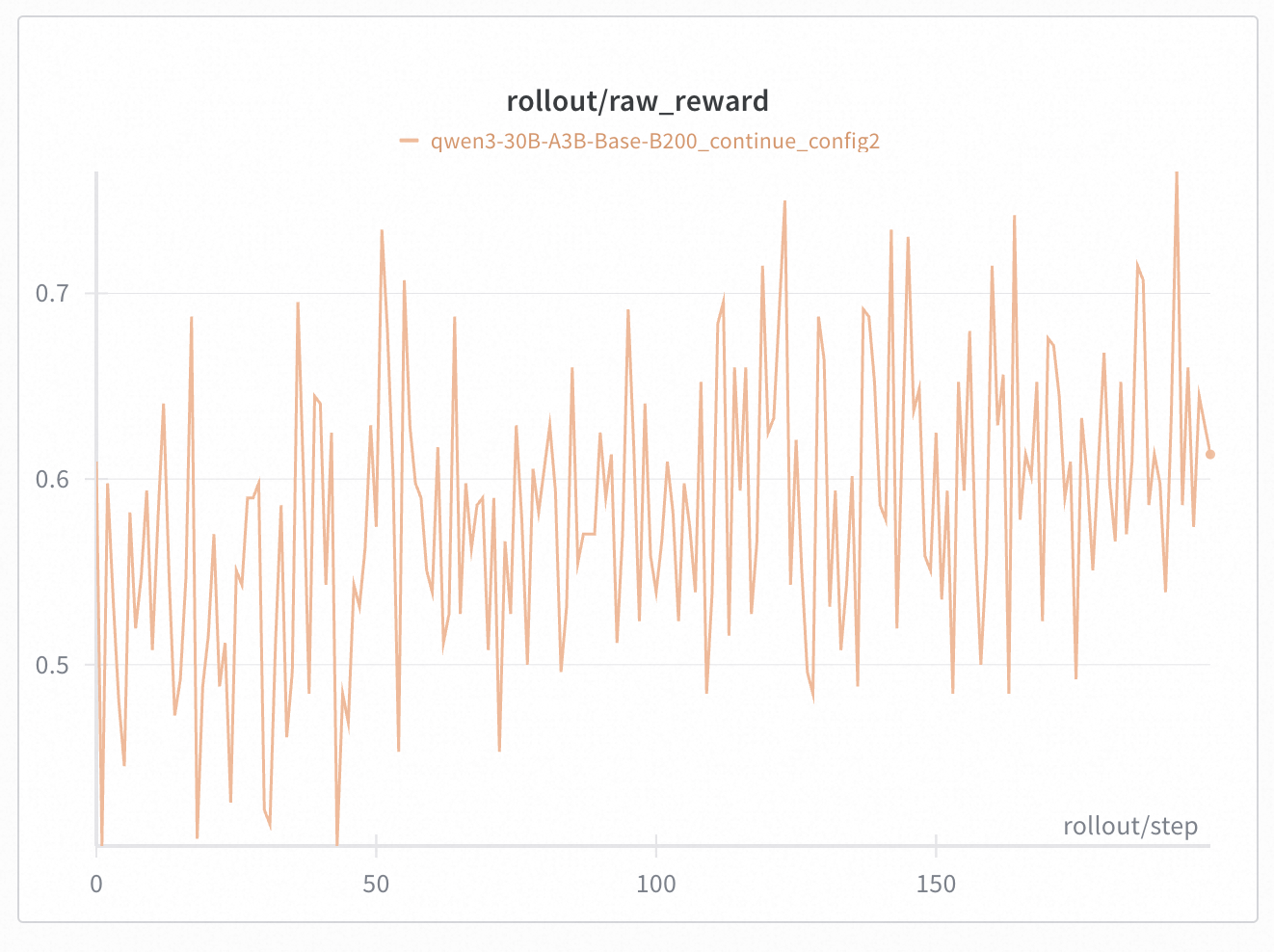
+
+
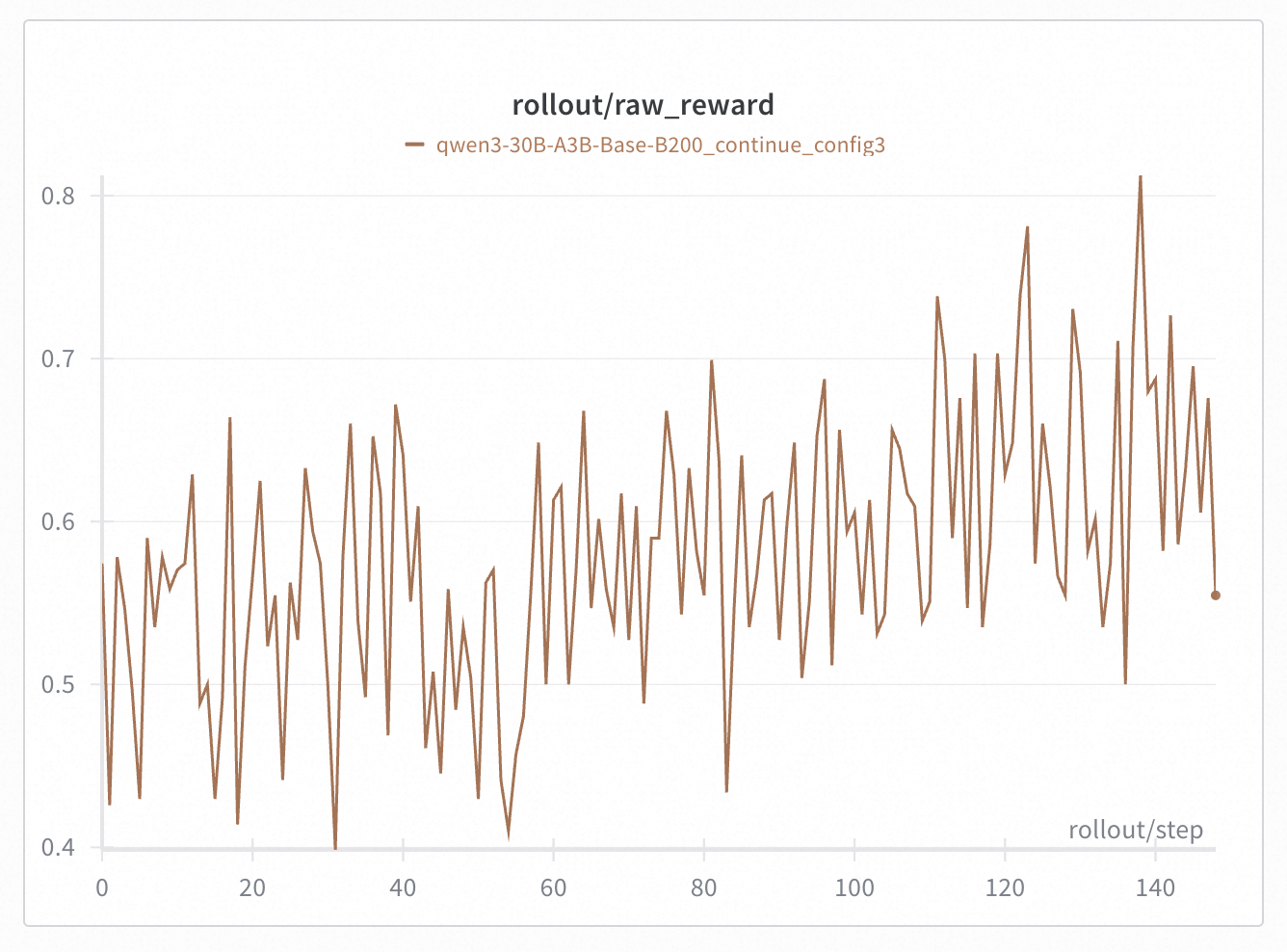
+
+
+Take All the Configurations into A Single Figure
+
+
+
+
+
+## Usage
+
+For more details, we provide complete guides and runnable examples:
+
+- Truly On Policy Training (FSDP): [Link](https://github.com/radixark/Miles/tree/main/examples/true_on_policy)
+- Algorithmic Mismatch Correction (Megatron): [Link](https://github.com/radixark/Miles/tree/main/examples/train_infer_mismatch_helper)
+
+If your goal is to fully eliminate the rollout–training mismatch, we recommend the Truly On Policy solution.
+
+If you prefer to retain high performance while mitigating mismatch, algorithmic correction such as [MIS](https://richardli.xyz/rl-collapse-3) is a lightweight and effective choice.
+
+Below is a brief overview of the available options.
+
+### Truly On Policy
+
+To open Truly On Policy mode for FSDP, add args:
+
+```bash
+CUSTOM_ARGS=(
+ --true-on-policy-mode
+)
+```
+
+For Megatron, to enable Truly On Policy mode is much more complicated, please refer to our later twitter announcement for details.
+
+### Algorithmic Mitigation
+
+> Please refer to [this link](https://github.com/radixark/Miles/blob/main/examples/train_infer_mismatch_helper/README.md) for a long and complete explanation of each attribute.
+
+Miles provides a comprehensive configuration system allowing users to flexibly balance Bias and Variance. To open Importance sampling, you must add the following attribute to your starting script.
+
+```bash
+CUSTOM_ARGS=(
+ --use-tis
+ --custom-config-path examples/train_infer_mismatch_helper/mis.yaml
+ --custom-tis-function-path examples.train_infer_mismatch_helper.mis.compute_mis_weights_with_cp
+)
+```
+
+Then you can adjust the detail configuration in [this link](https://github.com/radixark/Miles/blob/main/examples/train_infer_mismatch_helper/mis.yaml).
+
+
+IS Configuration Details
+
+In short, you can configure your correction strategy across four key dimensions:
+
+1. Calculation Levels
+
+This determines how important weights are aggregated from tokens to sequences.
+- **Token Level**
+ - Computes weights independently for each token.
+ - Characteristics: Computationally simple but mathematically biased. Suitable for most general scenarios.
+- **Sequence Level**
+ - The sequence weight is the product of all token weights.
+ - Characteristics: Mathematically unbiased but suffers from extreme variance. Recommended only when the mismatch is very small or the batch size is large.
+- **Geometric Level**
+ - Uses the geometric mean of all token weights as the sequence weight.
+ - Characteristics: A trade-off solution. It retains sequence-level information while avoiding the numerical instability of the product method, striking a balance between bias and variance. It also provides some length-invariant property for long-context tasks.
+
+2. Importance Weight Constraints & Trust Regions
+
+To prevent extreme importance weights from destabilizing training and to enforce a hard trust region, we apply specific constraints to the weights.
+
+- **IS Mode (Importance Sampling)**
+ - --tis-mode: Strategies include clip or truncate. This constrains importance weights to remain within the $[lower\_bound, upper\_bound]$ range, mitigating high variance.
+
+- **RS Mode (Rejection Sampling)**
+ - --use-rs: Instead of clipping weights, RS strictly discards (drops) tokens or sequences that fall outside the specified threshold. While this reduces the effective sample size, it ensures that the gradient update is calculated exclusively using data within the trust region ("gradient purity").
+
+- **Mask Mode (Masking)**
+ - --use-mask: This mode applies a mask to tokens or sequences falling outside the threshold during the gradient update. Unlike RS, this preserves the original batch structure (and nominal sample size), while effectively zeroing out the gradient contribution from invalid data.
+
+[MIS](https://richardli.xyz/rl-collapse-3) introduces combinations of IS and RS/Masking at different levels.
+
+3. Veto Mechanism
+
+This acts as a low-level safety net independent of IS/RS settings.
+- Mechanism: If a sequence contains any token with a probability lower than the veto threshold (e.g., $p < 10^{-6}$) under the old policy, the entire sequence is discarded.
+- Why it's needed: It prevents "catastrophic updates." Even if clipped, a token with near-zero probability in the denominator can introduce numerical instability or destructive gradients.
+
+4. Self-Normalization
+
+`--tis-batch-normalize`: Self-Normalization. Normalizes the importance weights across the entire batch so that their mean equals 1.0. This prevents the magnitude of weights from destabilizing the training step size.
+
+
+
+## More Mismatch-Solving Features
+
+In upstream Miles, you can also find additional mismatch-related tooling, for example:
+ - Unbiased KL estimation from Deepseek V3.2: [Link](https://github.com/THUDM/slime/pull/1004)
+ - Rollout routing replay: [Link](https://github.com/THUDM/slime/pull/715)
+ - Truly On Policy training for VLMs: [Link](https://github.com/radixark/Miles/tree/main/examples/true_on_policy_vlm)
+
+Any mismatch solving tool can be found in Miles!
+
+## Acknowledgments
+
+RadixArk Miles Team: Chenyang Zhao, Mao Cheng, Yueming Yuan, Jiajun Li, Banghua Zhu, Tom, Yusheng Su
+
+Bytedance Inc: Yingru Li, Jiacai Liu, Yuxuan Tong, Qian Liu, Hongyu Lu, Ziheng Jiang
+
+SGLang RL Team: Changyi Yang, Zhuohao Li, Nan Jiang, Chenxing Xie, Zilin Zhu, Ji Li, Yuzhen Zhou
+
+
+
+We sincerely thanks Qiwei Di, Xuheng Li, Heyang Zhao and Prof. Quanquan Gu from UCLA, as well as Liyuan Liu and Feng Yao from Thinking Machines Lab for their valuable suggestions and discussions. This idea of this work originated at the final weeks when Chenyang was a PhD student at UCLA and a student researcher at ByteDance Seed. Thanks to all the support along the way and Prof. Quanquan Gu for his guidance.
+
+## Reference
+
+1. When Speed Kills Stability: Demystifying RL collapse from the training-inference mismatch [blog](https://richardli.xyz/rl-collapse)
+ - Part 1: Why Off-Policy Breaks RL — An SGA Analysis Framework [blog](https://richardli.xyz/rl-collapse-1)
+ - Part 2: Applying the SGA Framework — Token v.s. Sequence-level Correction [blog](https://richardli.xyz/rl-collapse-2)
+ - Part 3: Trust Region Optimization via Sequence Masking [blog](https://richardli.xyz/rl-collapse-3)
+ - Mathematical Formulations of Rollout Correction Methods [docs](https://verl.readthedocs.io/en/latest/algo/rollout_corr_math.html)
+2. Your Efficient RL Framework Secretly Brings You Off-Policy RL Training [blog](https://fengyao.notion.site/off-policy-rl#279721e3f6c48092bbe2fcfe0e9c6b33)
+3. Simple statistical gradient-following algorithms for connectionist reinforcement learning. [link](https://link.springer.com/article/10.1007/BF00992696)
+4. Defeating Nondeterminism in LLM Inference [blog](https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/)
+5. Small Leak Can Sink a Great Ship—Boost RL Training on MoE with 𝑰𝒄𝒆𝑷𝒐𝒑! [blog](https://ringtech.notion.site/icepop)
+6. Batch size-invariance for policy optimization [link](https://arxiv.org/abs/2110.00641)
+7. AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning [link](https://arxiv.org/abs/2505.24298)
+8. [K3 KL-Definition](http://joschu.net/blog/kl-approx.html): $ k_3(x) = \frac{p(x)}{q(x)} - 1 - \log \frac{p(x)}{q(x)}$
diff --git a/package-lock.json b/package-lock.json
index 8d2db11cb..330d566ee 100644
--- a/package-lock.json
+++ b/package-lock.json
@@ -551,6 +551,7 @@
"resolved": "https://registry.npmjs.org/acorn/-/acorn-8.8.0.tgz",
"integrity": "sha512-QOxyigPVrpZ2GXT+PFyZTl6TtOFc5egxHIP9IlQ+RbupQuX4RkT/Bee4/kQuC02Xkzg84JcT7oLYtDIQxp+v7w==",
"dev": true,
+ "peer": true,
"bin": {
"acorn": "bin/acorn"
},
@@ -966,6 +967,7 @@
"url": "https://tidelift.com/funding/github/npm/browserslist"
}
],
+ "peer": true,
"dependencies": {
"caniuse-lite": "^1.0.30001400",
"electron-to-chromium": "^1.4.251",
@@ -1591,6 +1593,7 @@
"resolved": "https://registry.npmjs.org/eslint/-/eslint-8.17.0.tgz",
"integrity": "sha512-gq0m0BTJfci60Fz4nczYxNAlED+sMcihltndR8t9t1evnU/azx53x3t2UHXC/uRjcbvRw/XctpaNygSTcQD+Iw==",
"dev": true,
+ "peer": true,
"dependencies": {
"@eslint/eslintrc": "^1.3.0",
"@humanwhocodes/config-array": "^0.9.2",
@@ -1755,6 +1758,7 @@
"resolved": "https://registry.npmjs.org/eslint-plugin-import/-/eslint-plugin-import-2.26.0.tgz",
"integrity": "sha512-hYfi3FXaM8WPLf4S1cikh/r4IxnO6zrhZbEGz2b660EJRbuxgpDS5gkCuYgGWg2xxh2rBuIr4Pvhve/7c31koA==",
"dev": true,
+ "peer": true,
"dependencies": {
"array-includes": "^3.1.4",
"array.prototype.flat": "^1.2.5",
@@ -2049,7 +2053,8 @@
"node_modules/eve": {
"version": "0.5.4",
"resolved": "https://registry.npmjs.org/eve/-/eve-0.5.4.tgz",
- "integrity": "sha512-aqprQ9MAOh1t66PrHxDFmMXPlgNO6Uv1uqvxmwjprQV50jaQ2RqO7O1neY4PJwC+hMnkyMDphu2AQPOPZdjQog=="
+ "integrity": "sha512-aqprQ9MAOh1t66PrHxDFmMXPlgNO6Uv1uqvxmwjprQV50jaQ2RqO7O1neY4PJwC+hMnkyMDphu2AQPOPZdjQog==",
+ "peer": true
},
"node_modules/expand-template": {
"version": "2.0.3",
@@ -3285,6 +3290,7 @@
"version": "12.1.6",
"resolved": "https://registry.npmjs.org/next/-/next-12.1.6.tgz",
"integrity": "sha512-cebwKxL3/DhNKfg9tPZDQmbRKjueqykHHbgaoG4VBRH3AHQJ2HO0dbKFiS1hPhe1/qgc2d/hFeadsbPicmLD+A==",
+ "peer": true,
"dependencies": {
"@next/env": "12.1.6",
"caniuse-lite": "^1.0.30001332",
@@ -3656,6 +3662,7 @@
"url": "https://tidelift.com/funding/github/npm/postcss"
}
],
+ "peer": true,
"dependencies": {
"nanoid": "^3.3.4",
"picocolors": "^1.0.0",
@@ -3928,6 +3935,7 @@
"version": "18.1.0",
"resolved": "https://registry.npmjs.org/react/-/react-18.1.0.tgz",
"integrity": "sha512-4oL8ivCz5ZEPyclFQXaNksK3adutVS8l2xzZU0cqEFrE9Sb7fC0EFK5uEk74wIreL1DERyjvsU915j1pcT2uEQ==",
+ "peer": true,
"dependencies": {
"loose-envify": "^1.1.0"
},
@@ -3958,6 +3966,7 @@
"version": "18.1.0",
"resolved": "https://registry.npmjs.org/react-dom/-/react-dom-18.1.0.tgz",
"integrity": "sha512-fU1Txz7Budmvamp7bshe4Zi32d0ll7ect+ccxNu9FlObT605GOEB8BfO4tmRJ39R5Zj831VCpvQ05QPBW5yb+w==",
+ "peer": true,
"dependencies": {
"loose-envify": "^1.1.0",
"scheduler": "^0.22.0"
@@ -4828,6 +4837,7 @@
"version": "4.8.4",
"resolved": "https://registry.npmjs.org/typescript/-/typescript-4.8.4.tgz",
"integrity": "sha512-QCh+85mCy+h0IGff8r5XWzOVSbBO+KfeYrMQh7NJ58QujwcE22u+NUSmUxqF+un70P9GXKxa2HCNiTTMJknyjQ==",
+ "peer": true,
"bin": {
"tsc": "bin/tsc",
"tsserver": "bin/tsserver"
@@ -5330,7 +5340,8 @@
"version": "8.8.0",
"resolved": "https://registry.npmjs.org/acorn/-/acorn-8.8.0.tgz",
"integrity": "sha512-QOxyigPVrpZ2GXT+PFyZTl6TtOFc5egxHIP9IlQ+RbupQuX4RkT/Bee4/kQuC02Xkzg84JcT7oLYtDIQxp+v7w==",
- "dev": true
+ "dev": true,
+ "peer": true
},
"acorn-jsx": {
"version": "5.3.2",
@@ -5633,6 +5644,7 @@
"resolved": "https://registry.npmjs.org/browserslist/-/browserslist-4.21.4.tgz",
"integrity": "sha512-CBHJJdDmgjl3daYjN5Cp5kbTf1mUhZoS+beLklHIvkOWscs83YAhLlF3Wsh/lciQYAcbBJgTOD44VtG31ZM4Hw==",
"dev": true,
+ "peer": true,
"requires": {
"caniuse-lite": "^1.0.30001400",
"electron-to-chromium": "^1.4.251",
@@ -6069,6 +6081,7 @@
"resolved": "https://registry.npmjs.org/eslint/-/eslint-8.17.0.tgz",
"integrity": "sha512-gq0m0BTJfci60Fz4nczYxNAlED+sMcihltndR8t9t1evnU/azx53x3t2UHXC/uRjcbvRw/XctpaNygSTcQD+Iw==",
"dev": true,
+ "peer": true,
"requires": {
"@eslint/eslintrc": "^1.3.0",
"@humanwhocodes/config-array": "^0.9.2",
@@ -6199,6 +6212,7 @@
"resolved": "https://registry.npmjs.org/eslint-plugin-import/-/eslint-plugin-import-2.26.0.tgz",
"integrity": "sha512-hYfi3FXaM8WPLf4S1cikh/r4IxnO6zrhZbEGz2b660EJRbuxgpDS5gkCuYgGWg2xxh2rBuIr4Pvhve/7c31koA==",
"dev": true,
+ "peer": true,
"requires": {
"array-includes": "^3.1.4",
"array.prototype.flat": "^1.2.5",
@@ -6414,7 +6428,8 @@
"eve": {
"version": "0.5.4",
"resolved": "https://registry.npmjs.org/eve/-/eve-0.5.4.tgz",
- "integrity": "sha512-aqprQ9MAOh1t66PrHxDFmMXPlgNO6Uv1uqvxmwjprQV50jaQ2RqO7O1neY4PJwC+hMnkyMDphu2AQPOPZdjQog=="
+ "integrity": "sha512-aqprQ9MAOh1t66PrHxDFmMXPlgNO6Uv1uqvxmwjprQV50jaQ2RqO7O1neY4PJwC+hMnkyMDphu2AQPOPZdjQog==",
+ "peer": true
},
"expand-template": {
"version": "2.0.3",
@@ -7341,6 +7356,7 @@
"version": "12.1.6",
"resolved": "https://registry.npmjs.org/next/-/next-12.1.6.tgz",
"integrity": "sha512-cebwKxL3/DhNKfg9tPZDQmbRKjueqykHHbgaoG4VBRH3AHQJ2HO0dbKFiS1hPhe1/qgc2d/hFeadsbPicmLD+A==",
+ "peer": true,
"requires": {
"@next/env": "12.1.6",
"@next/swc-android-arm-eabi": "12.1.6",
@@ -7590,6 +7606,7 @@
"version": "8.4.17",
"resolved": "https://registry.npmjs.org/postcss/-/postcss-8.4.17.tgz",
"integrity": "sha512-UNxNOLQydcOFi41yHNMcKRZ39NeXlr8AxGuZJsdub8vIb12fHzcq37DTU/QtbI6WLxNg2gF9Z+8qtRwTj1UI1Q==",
+ "peer": true,
"requires": {
"nanoid": "^3.3.4",
"picocolors": "^1.0.0",
@@ -7760,6 +7777,7 @@
"version": "18.1.0",
"resolved": "https://registry.npmjs.org/react/-/react-18.1.0.tgz",
"integrity": "sha512-4oL8ivCz5ZEPyclFQXaNksK3adutVS8l2xzZU0cqEFrE9Sb7fC0EFK5uEk74wIreL1DERyjvsU915j1pcT2uEQ==",
+ "peer": true,
"requires": {
"loose-envify": "^1.1.0"
}
@@ -7780,6 +7798,7 @@
"version": "18.1.0",
"resolved": "https://registry.npmjs.org/react-dom/-/react-dom-18.1.0.tgz",
"integrity": "sha512-fU1Txz7Budmvamp7bshe4Zi32d0ll7ect+ccxNu9FlObT605GOEB8BfO4tmRJ39R5Zj831VCpvQ05QPBW5yb+w==",
+ "peer": true,
"requires": {
"loose-envify": "^1.1.0",
"scheduler": "^0.22.0"
@@ -8413,7 +8432,8 @@
"typescript": {
"version": "4.8.4",
"resolved": "https://registry.npmjs.org/typescript/-/typescript-4.8.4.tgz",
- "integrity": "sha512-QCh+85mCy+h0IGff8r5XWzOVSbBO+KfeYrMQh7NJ58QujwcE22u+NUSmUxqF+un70P9GXKxa2HCNiTTMJknyjQ=="
+ "integrity": "sha512-QCh+85mCy+h0IGff8r5XWzOVSbBO+KfeYrMQh7NJ58QujwcE22u+NUSmUxqF+un70P9GXKxa2HCNiTTMJknyjQ==",
+ "peer": true
},
"uc.micro": {
"version": "1.0.6",
diff --git a/public/images/blog/mismatch/mismatch-preview.png b/public/images/blog/mismatch/mismatch-preview.png
new file mode 100644
index 000000000..94296b881
Binary files /dev/null and b/public/images/blog/mismatch/mismatch-preview.png differ