diff --git a/docs/toolchain/appendix/app_flow_manual.md b/docs/toolchain/appendix/app_flow_manual.md
index 8735f14..cd4716a 100644
--- a/docs/toolchain/appendix/app_flow_manual.md
+++ b/docs/toolchain/appendix/app_flow_manual.md
@@ -91,7 +91,7 @@ The memory layout for the output node data after CSIM inference is different bet
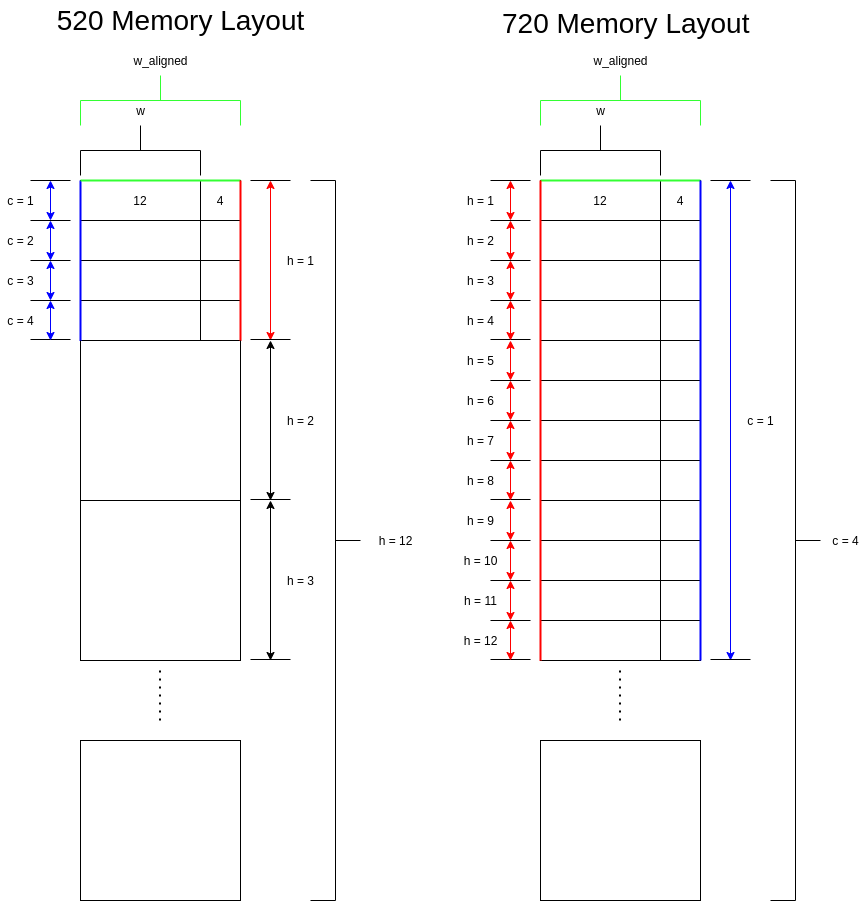
Let's look at an example where c = 4, h = 12, and w = 12. Indexing starts at 0 for this example.
-

+
Memory layouts
-

+
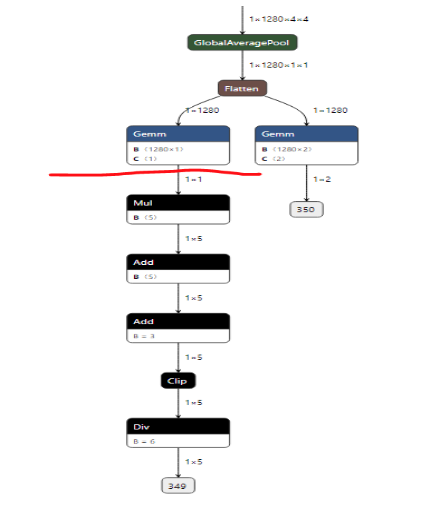
Figure 4. Pre-edited model
-

+
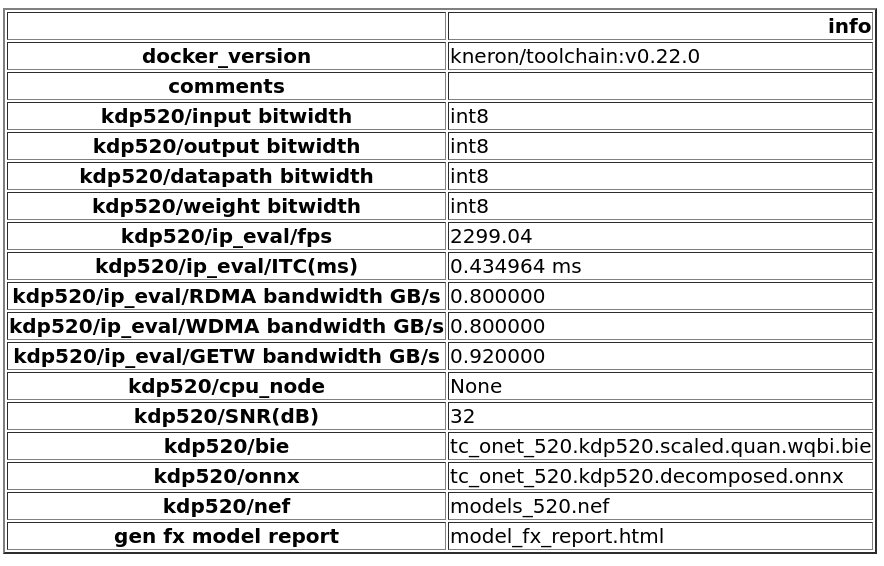
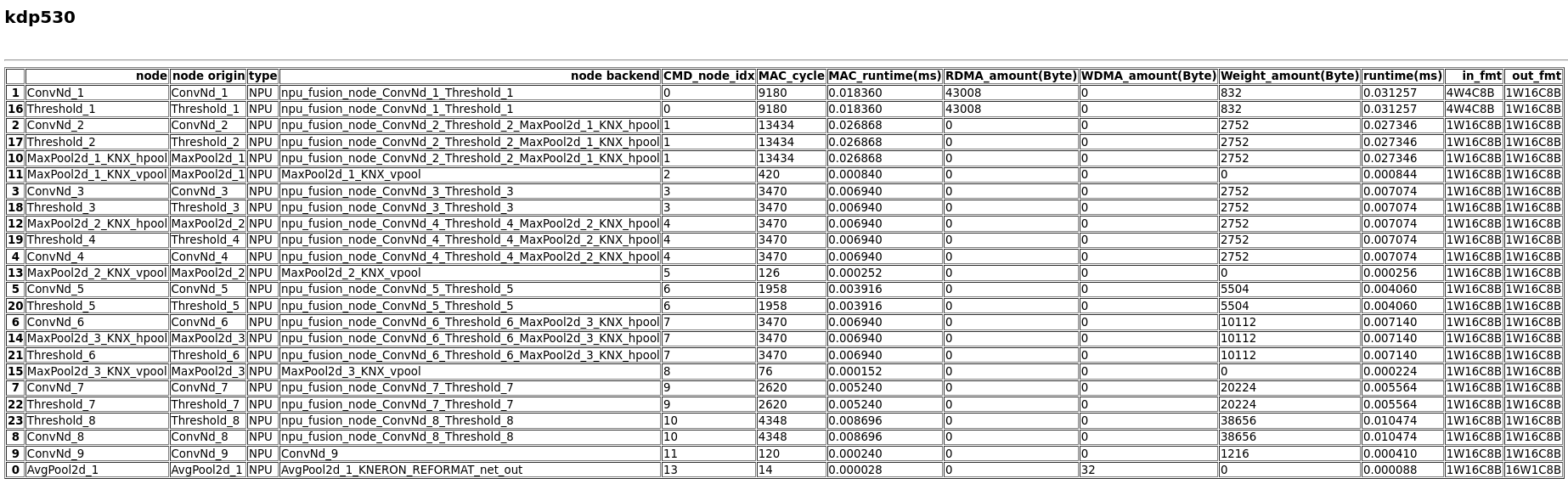
Figure 1. Summary for platform 520, mode 0 (IP evaluator only)
-

+
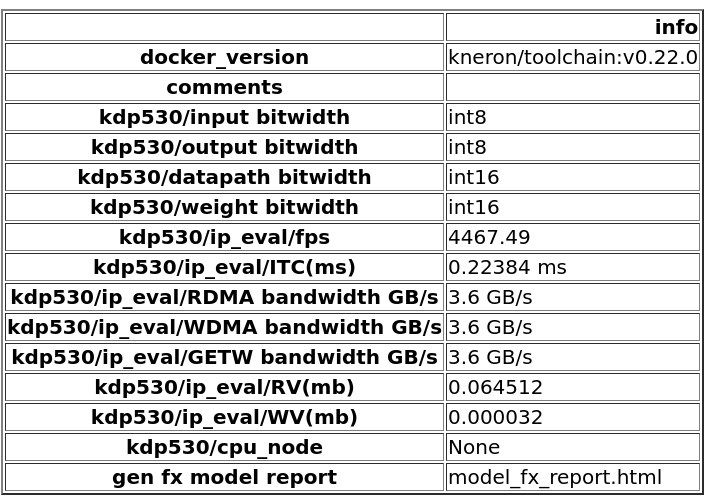
Figure 2. Summary for platform 530, mode 0 (IP evaluator only)
-

+
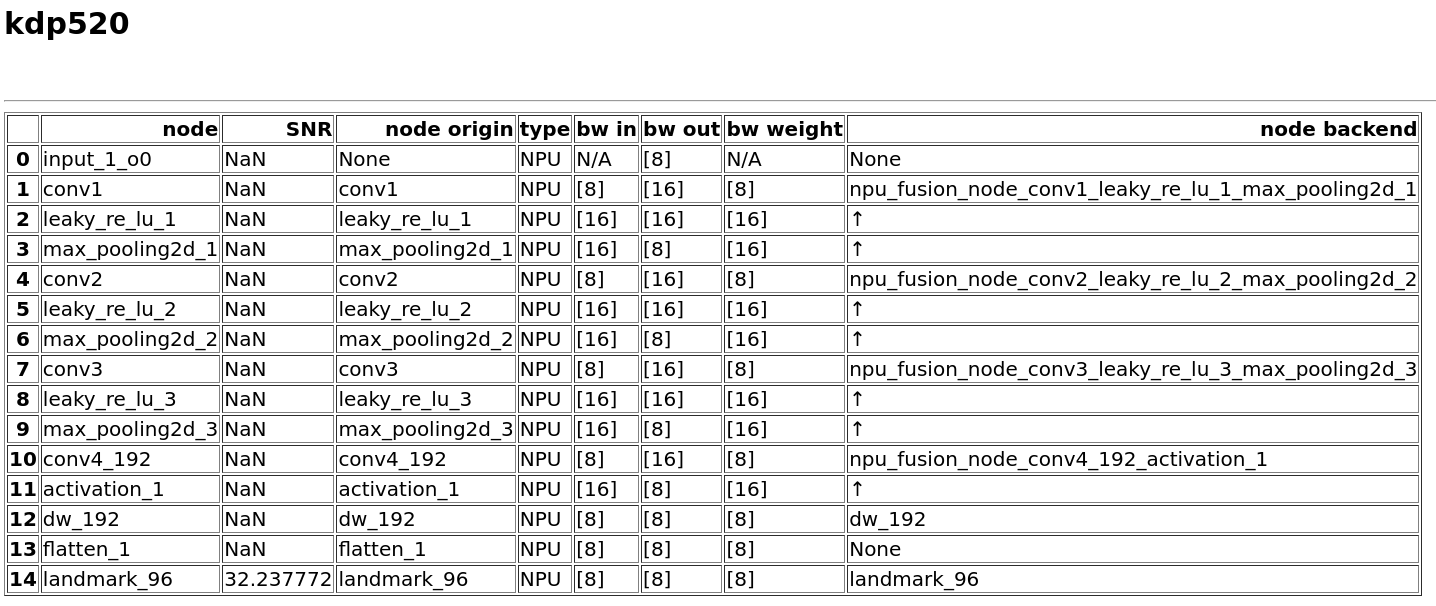
Figure 3. Summary for platform 520, mode 1 (with fixed-point model generated)
-

+
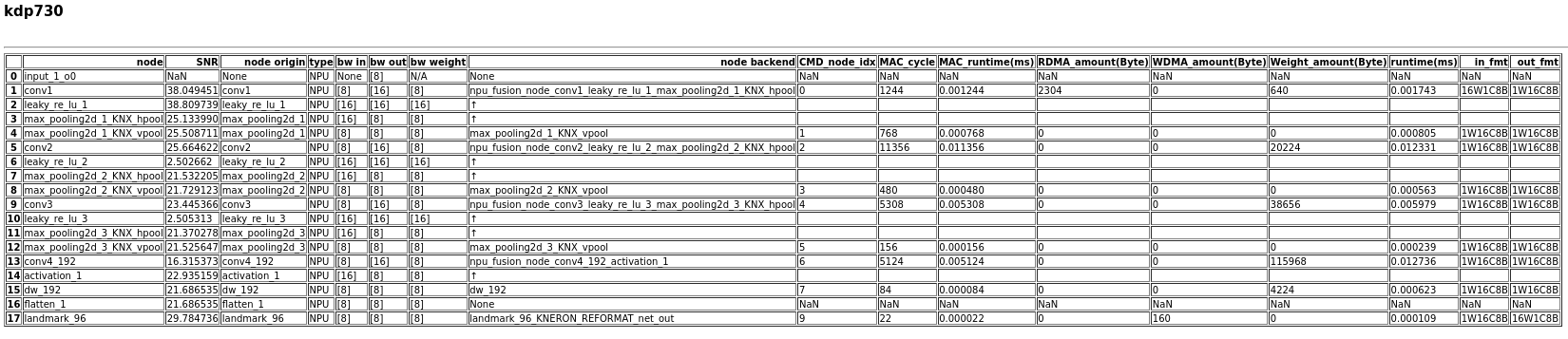
Figure 4. Summary for platform 730, mode 2 (with fixed-point model generated and snr check.)
-

+
Figure 5. Node details for platform 520, mode 0 (IP evaluator only).
-

+
Figure 6. Node details for platform 530, mode 0 (IP evaluator only).
-

+
Figure 7. Node details for platform 520, mode 1 (with fixed-point model generated).
-

+
Figure 8. Node details for platform 730, mode 2 (with fixed-point model generated and SNR check).
 +
Notes:
diff --git a/docs/toolchain/appendix/yolo_example.md b/docs/toolchain/appendix/yolo_example.md
index 9f93f3e..94ad2c4 100644
--- a/docs/toolchain/appendix/yolo_example.md
+++ b/docs/toolchain/appendix/yolo_example.md
@@ -95,7 +95,7 @@ Now, we go through all toolchain flow by KTC (Kneron Toolchain) using the Python
* Run "python" or 'ipython'to open to Python shell:
+
Notes:
diff --git a/docs/toolchain/appendix/yolo_example.md b/docs/toolchain/appendix/yolo_example.md
index 9f93f3e..94ad2c4 100644
--- a/docs/toolchain/appendix/yolo_example.md
+++ b/docs/toolchain/appendix/yolo_example.md
@@ -95,7 +95,7 @@ Now, we go through all toolchain flow by KTC (Kneron Toolchain) using the Python
* Run "python" or 'ipython'to open to Python shell:
-

+
Figure 1. python shell
-

+
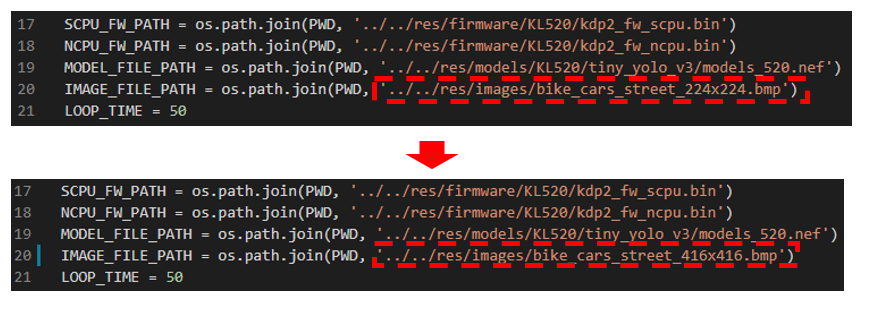
Figure 2. modify input image in example
-

+
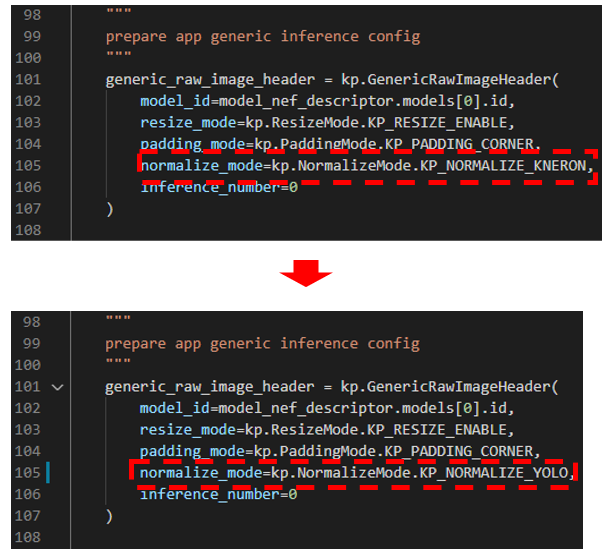
Figure 3. modify normalization method in example
-

+
Figure 4. detection result
-
+
Figure 1. python shell
-

+
-

+
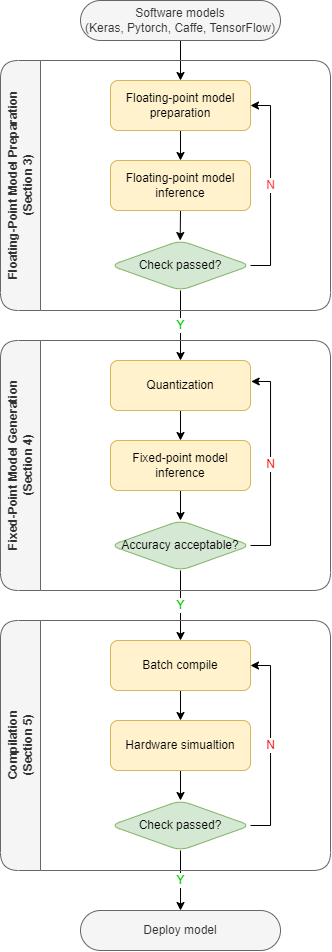
Figure 1. Diagram of working flow
-

+
Figure 1. PTQ Chart
-

+
Figure 1. SNR-FPS Chart
-

+
Figure 2. Sentivity Analysis
 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+