)
@@ -588,7 +588,7 @@ When IPL (Initial Program Loader) in ROM starts to run on SCPU after power-on or
Both SCPU and NCPU firmware run RTOS with SCPU handling application, media input/output and peripheral drivers and NCPU handling CNN model pre/post processing. Two CPUs use interrupts and shared memory to achieve IPC (Inter Processor Communication).
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-

+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
-

+
P_n&space; "AP = \sum_n (R_n-R_{n-1})P_n") +
-where
+
-where  and
and  are the precision and recall at the nth threshold. The mAP compares the ground-truth bounding box to the detected box and returns a score. The higher the score, the more accurate the model is in its detections.
+where and are the precision and recall at the nth threshold. The mAP compares the ground-truth bounding box to the detected box and returns a score. The higher the score, the more accurate the model is in its detections.
## Evaluation on a Dataset
For evaluating the trained model on dataset:
diff --git a/docs/model_training/object_detection_yolov5.md b/docs/model_training/object_detection_yolov5.md
index c2fde03..9090d79 100644
--- a/docs/model_training/object_detection_yolov5.md
+++ b/docs/model_training/object_detection_yolov5.md
@@ -41,12 +41,12 @@ After using a tool like [CVAT](https://github.com/openvinotoolkit/cvat), [makese
- Class numbers are zero-indexed (start from 0).
are the precision and recall at the nth threshold. The mAP compares the ground-truth bounding box to the detected box and returns a score. The higher the score, the more accurate the model is in its detections.
+where and are the precision and recall at the nth threshold. The mAP compares the ground-truth bounding box to the detected box and returns a score. The higher the score, the more accurate the model is in its detections.
## Evaluation on a Dataset
For evaluating the trained model on dataset:
diff --git a/docs/model_training/object_detection_yolov5.md b/docs/model_training/object_detection_yolov5.md
index c2fde03..9090d79 100644
--- a/docs/model_training/object_detection_yolov5.md
+++ b/docs/model_training/object_detection_yolov5.md
@@ -41,12 +41,12 @@ After using a tool like [CVAT](https://github.com/openvinotoolkit/cvat), [makese
- Class numbers are zero-indexed (start from 0).
-

+
-

+
-

+
Memory layouts
-

+
Figure 4. Pre-edited model
-

+
Figure 1. Summary for platform 520, mode 0 (ip evaluator only)
-

+
Figure 2. Summary for platform 530, mode 0 (ip evaluator only)
-

+
Figure 3. Summary for platform 520, mode 1 (with fix model generated)
-

+
Figure 4. Summary for platform 730, model 2 (with fix model generated and snr check.)
-

+
Figure 5. Node details for platform 520, mode 0 (ip evaluator only).
-

+
Figure 6. Node details for platform 530, mode 0 (ip evaluator only).
-

+
Figure 7. Node details for platform 520, mode 1 (with fix model generated).
-

+
Figure 8. NOde details for platform 730, mode 2 (with fix model generated and snr check).
 +
Notes:
diff --git a/docs/toolchain/appendix/yolo_example.md b/docs/toolchain/appendix/yolo_example.md
index 5f6f40d..cedbf97 100644
--- a/docs/toolchain/appendix/yolo_example.md
+++ b/docs/toolchain/appendix/yolo_example.md
@@ -95,7 +95,7 @@ Now, we go through all toolchain flow by KTC (Kneron Toolchain) using the Python
* Run "python" or 'ipython'to open to Python shell:
+
Notes:
diff --git a/docs/toolchain/appendix/yolo_example.md b/docs/toolchain/appendix/yolo_example.md
index 5f6f40d..cedbf97 100644
--- a/docs/toolchain/appendix/yolo_example.md
+++ b/docs/toolchain/appendix/yolo_example.md
@@ -95,7 +95,7 @@ Now, we go through all toolchain flow by KTC (Kneron Toolchain) using the Python
* Run "python" or 'ipython'to open to Python shell:
-

+
Figure 1. python shell
-

+
Figure 2. modify input image in example
-

+
Figure 3. modify normalization method in example
-

+
Figure 4. detection result
-
+
Figure 1. python shell
-

+
-

+
Figure 1. Diagram of working flow
-
+
Figure FAQ3.1 VirtualBox
-
+
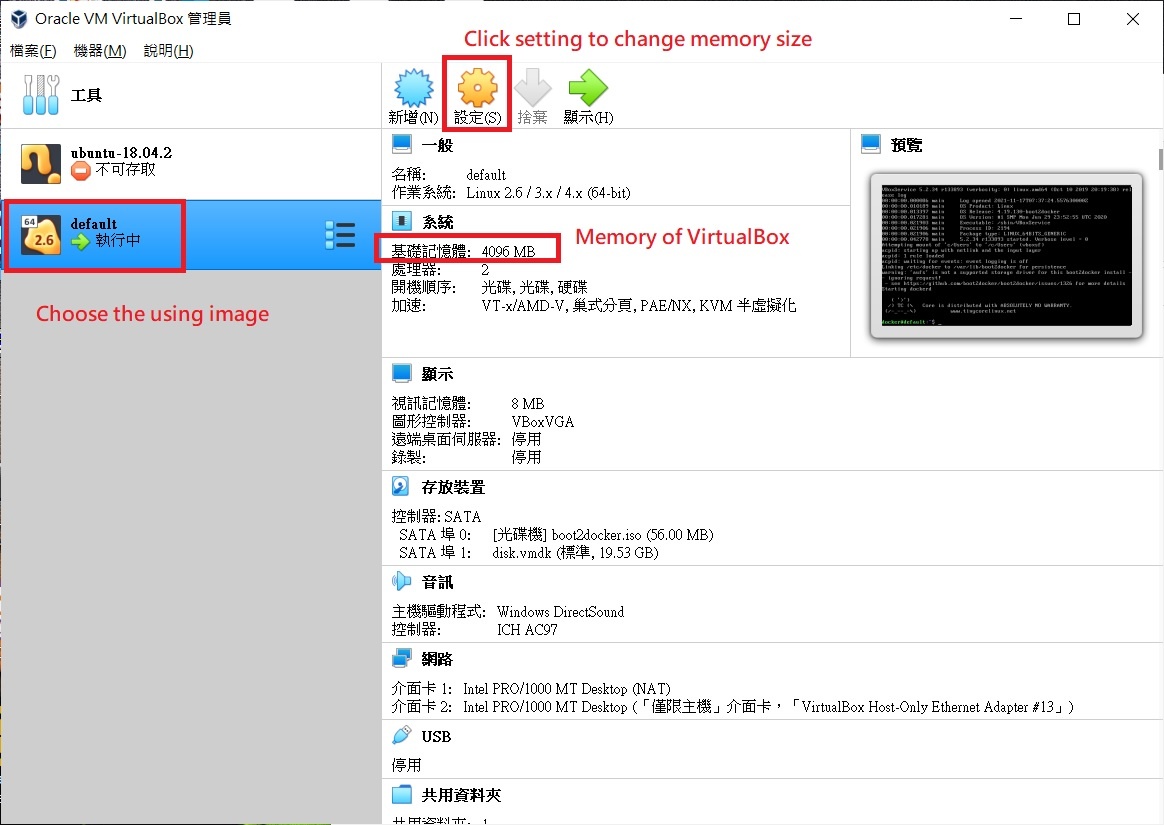
Figure FAQ3.2 VM status
-
+
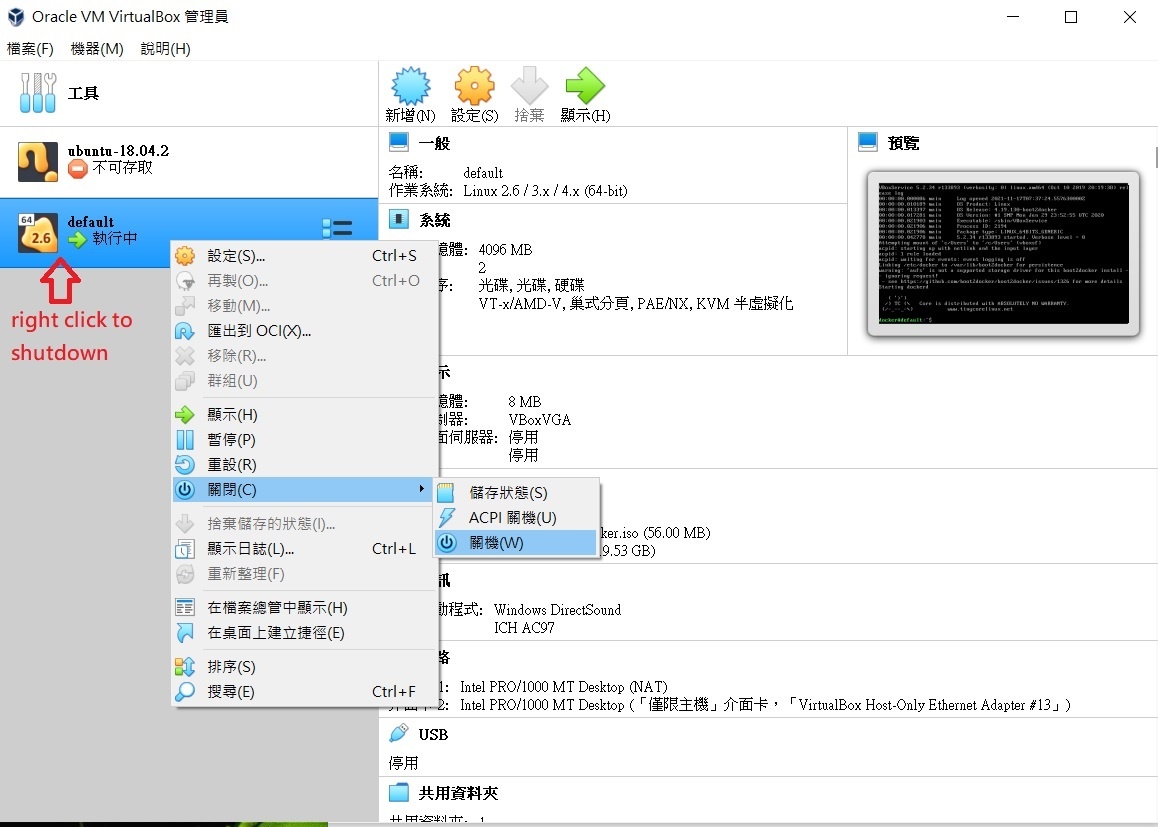
Figure FAQ3.3 VM shutdown
-
+
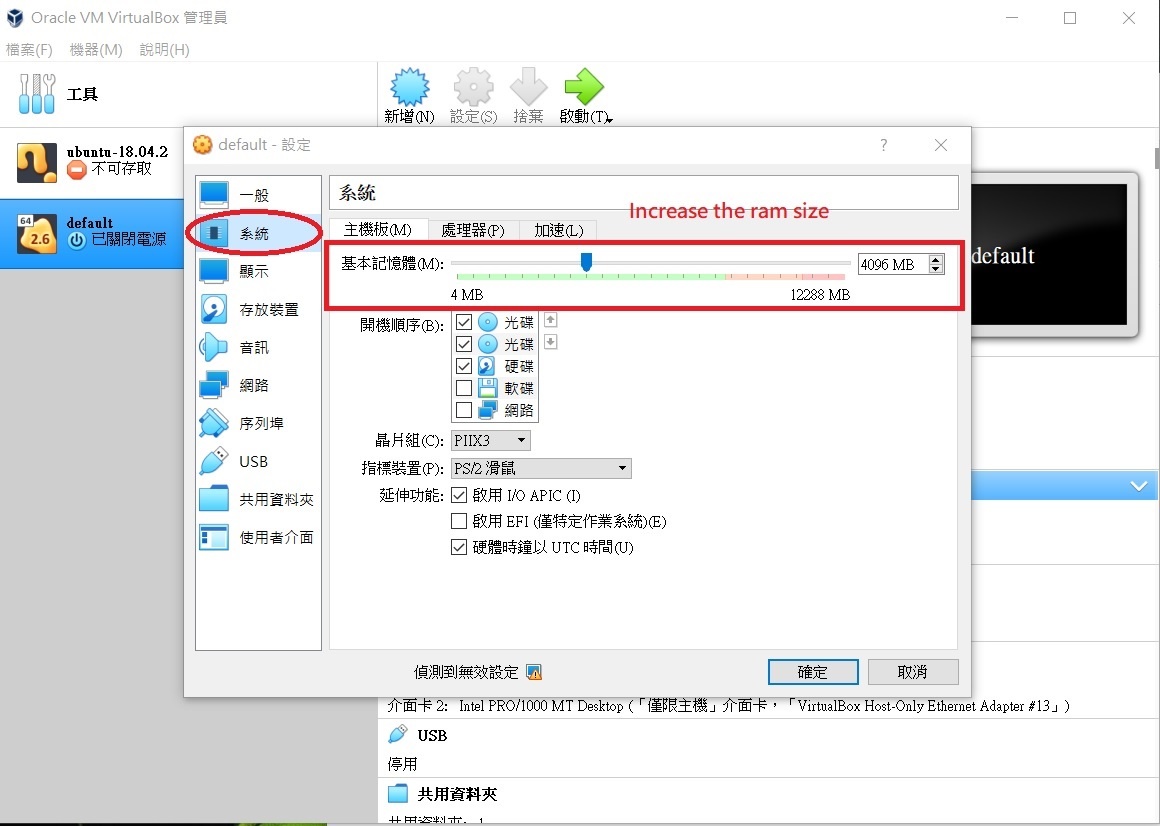
Figure FAQ3.4 VM settings
-

+
Figure 1. PTQ Chart
-

+
Figure 1. SNR-FPS Chart
-

+
Figure 2. Sentivity Analysis
 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+
 +
+